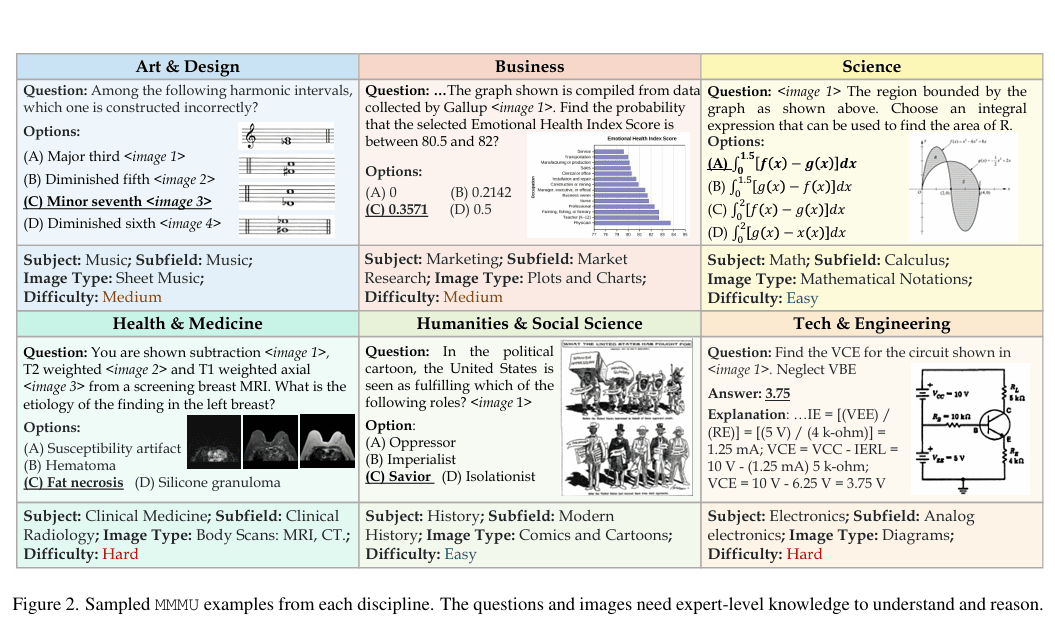
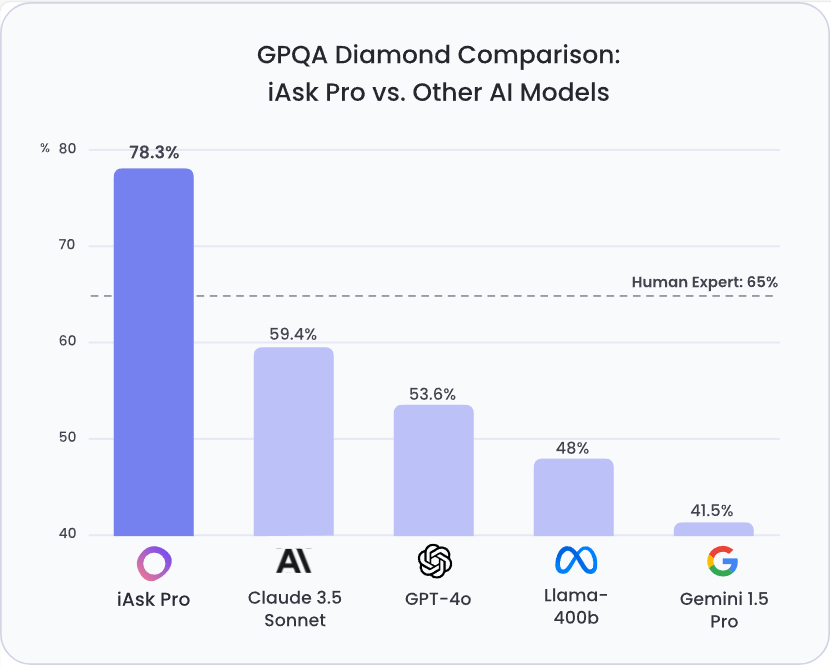
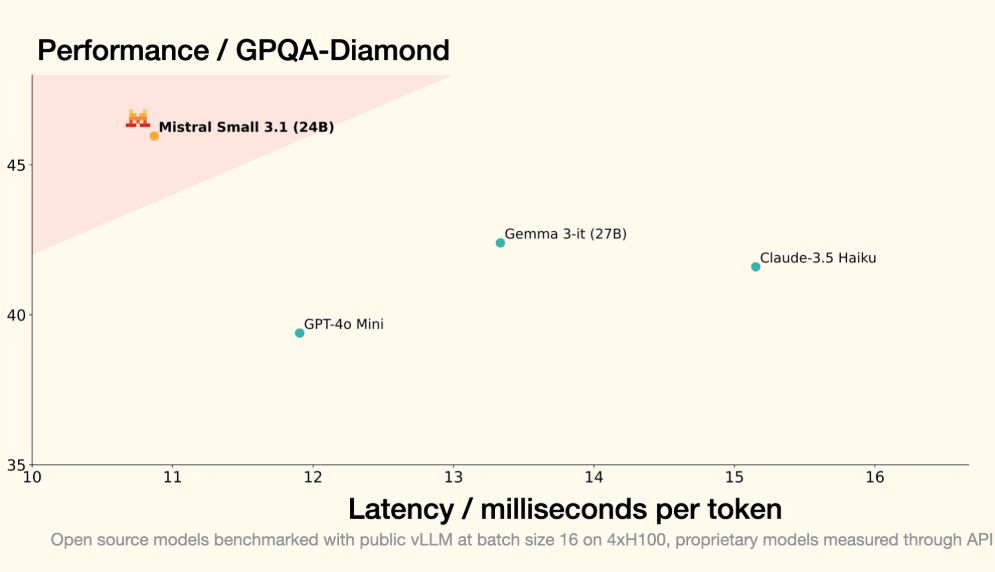
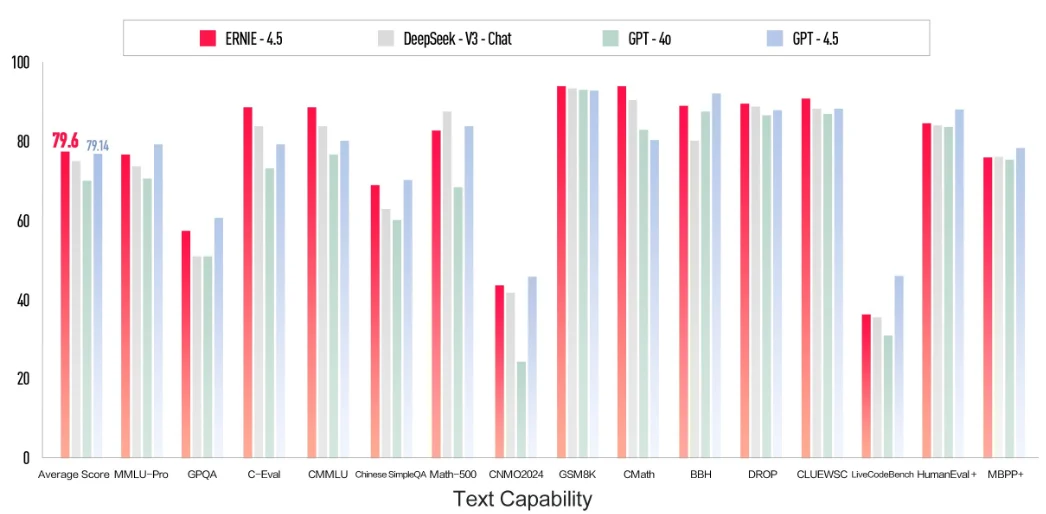
法国人工智能初创企业MistralAI发布首个推理模型Magistral:纯RL训练,多语言能力出色,推理速度很快,Magistral Small (24B)版本免费开源,但面对Qwen3和DeepSeek稍显乏力
Mistral AI今天发布了其首个专注于推理能力的系列模型——**Magistral**。这次发布包含两个核心模型:旗舰模型`Magistral Medium`和<font color=red>已开源的</font>`Magistral Small (24B)`。最引人注目的亮点是,Mistral展示了其自研的强化学习(RL)pipeline能够从头开始,仅通过RL训练就将基础模型的推理能力提升到业界顶尖水平,而无需依赖任何其他预先存在的推理模型进行数据蒸馏。这套技术栈非常强大!