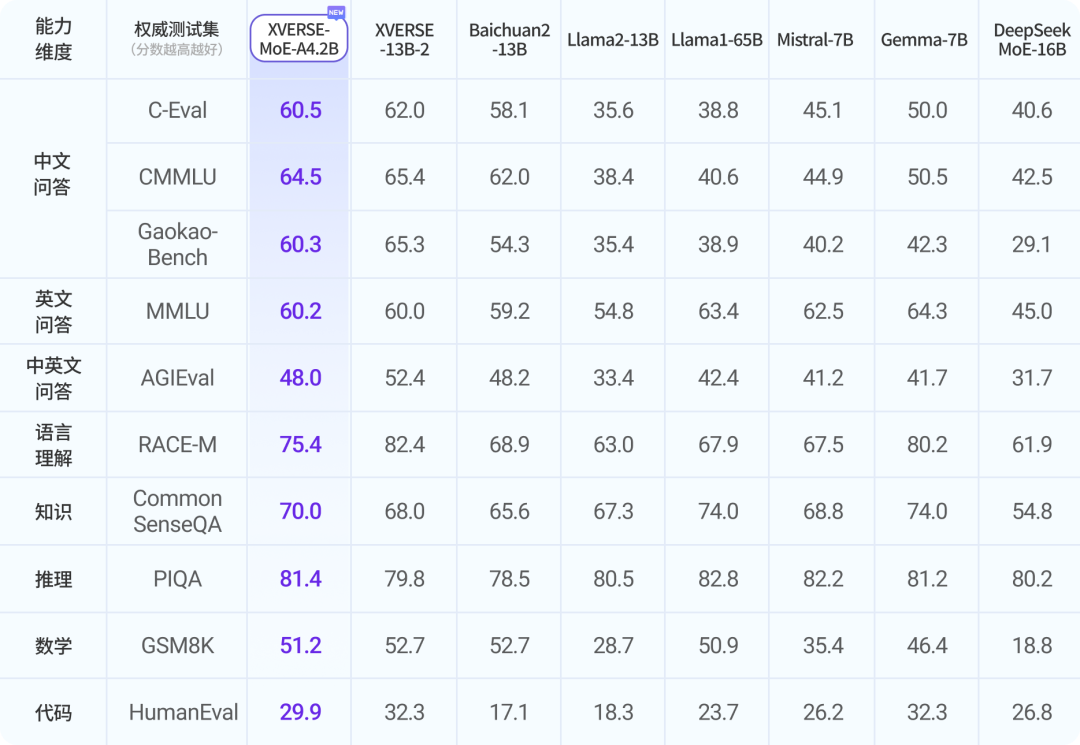
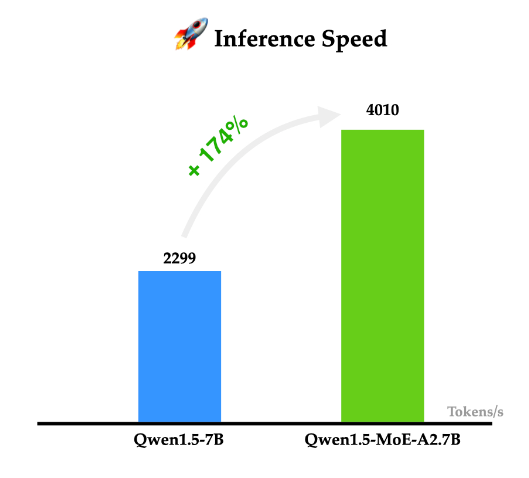
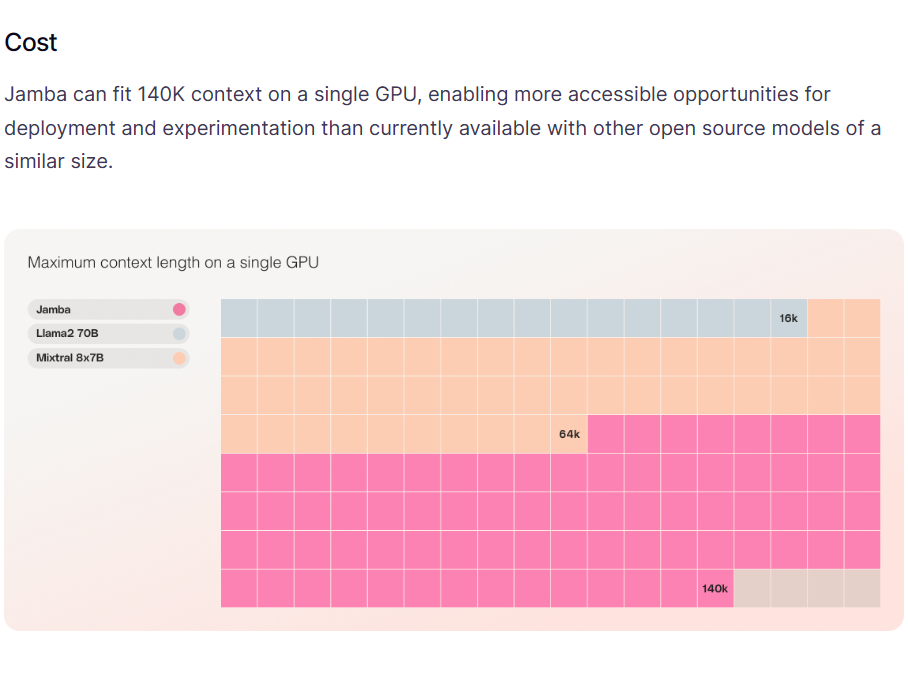
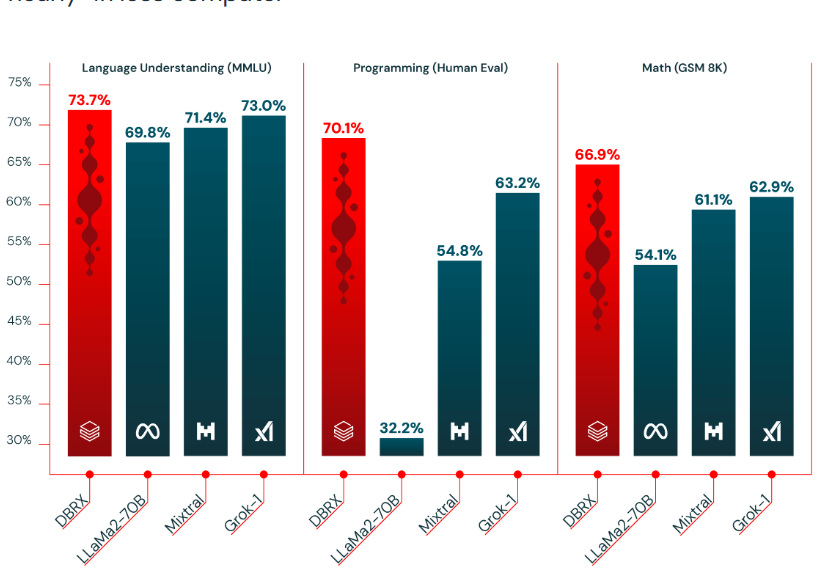
阿里开源推理大模型QwQ-32B-Preview:开源领域对OpenAI o1模型奋起直追,能力接近o1-mini,超过GPT-4o!
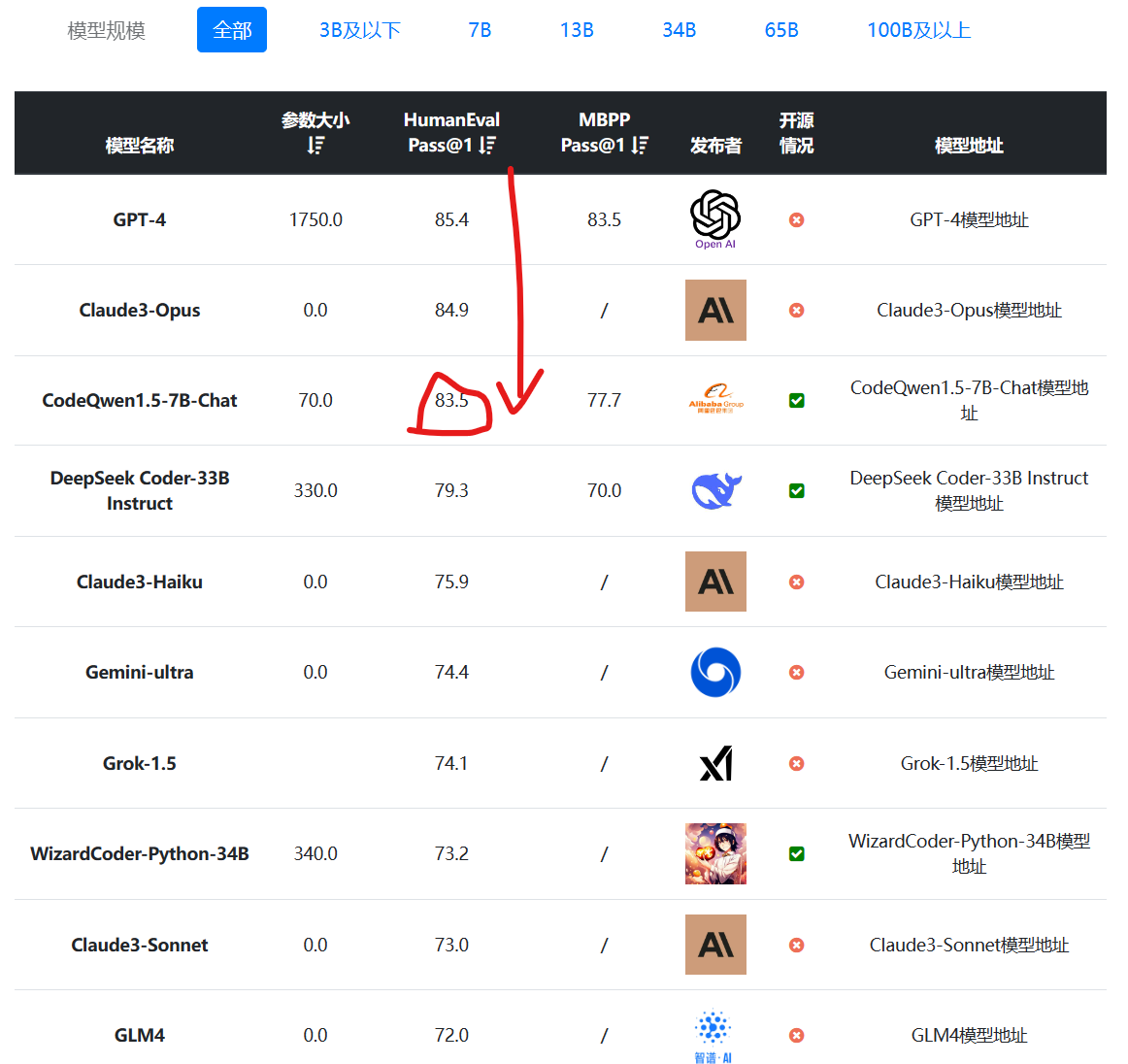
随着OpenAI发布推理大模型o1,专注于推理能力的大模型开始被广泛关注。基于思维链探索的推理大模型也不断涌现。此前,DeepSeekAI与上海人工智能实验室都发布过推理大模型,也展现了很不错的推理能力,虽然DeepSeekAI官方承诺该模型会开源,但是目前还没有发布。今天,阿里开源了一个全新的推理大模型QwQ-32B-Preview,其推理能力在评测结果上超过o1-mini,是目前开源领域最强的推理大模型(也可能是目前唯一)。