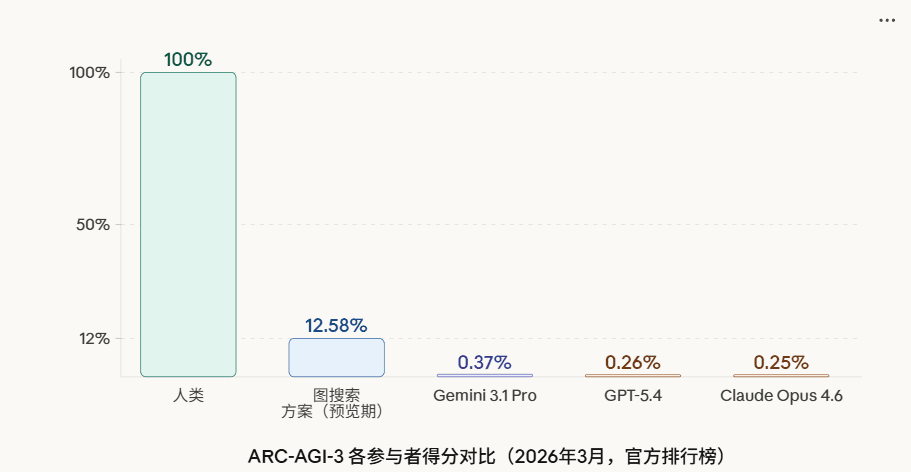
ClawBench:针对OpenClaw场景的大模型智能体(LLM Agent)的评测基准。
ClawBench 是针对大模型智能体(LLM Agent)的评测基准。它通过隔离沙盒环境中的真实企业工作流任务,评估大模型在实际部署场景下的表现,与传统问答式或合成数据集基准形成区别。ClawBench 与 PinchBench 均服务于 OpenClaw 生态,但二者侧重点不同:PinchBench 是 OpenClaw 官方基准,由 kilo.ai 团队开发,聚焦 23 类真实任务的成功率、速度和成本;ClawBench 则独立构建,包含 30 个高级任务,覆盖 5 大核心业务场景,采用混合评分机制