大模型评测的新标杆:超高难度的“Humanity’s Last Exam”(HLE)介绍
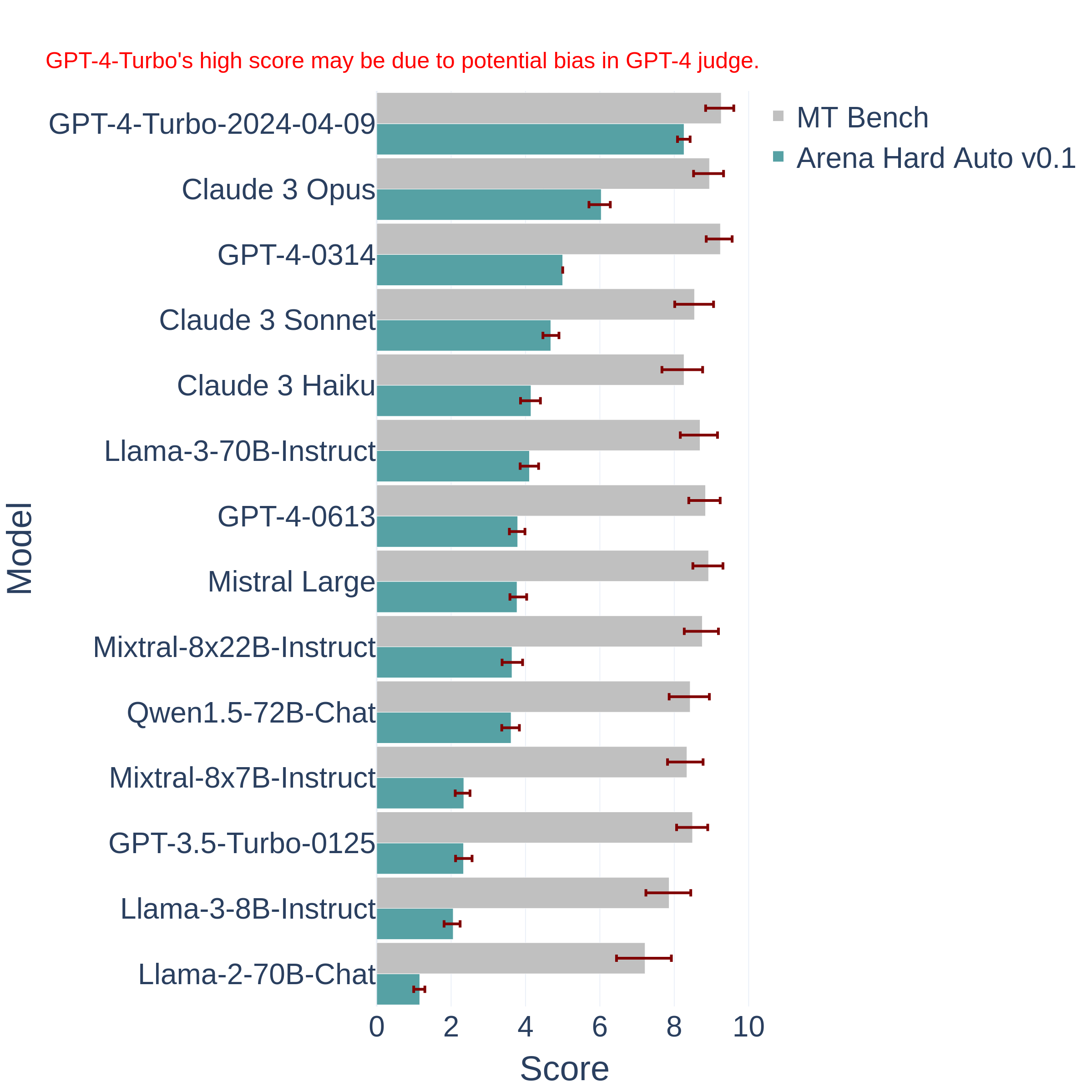
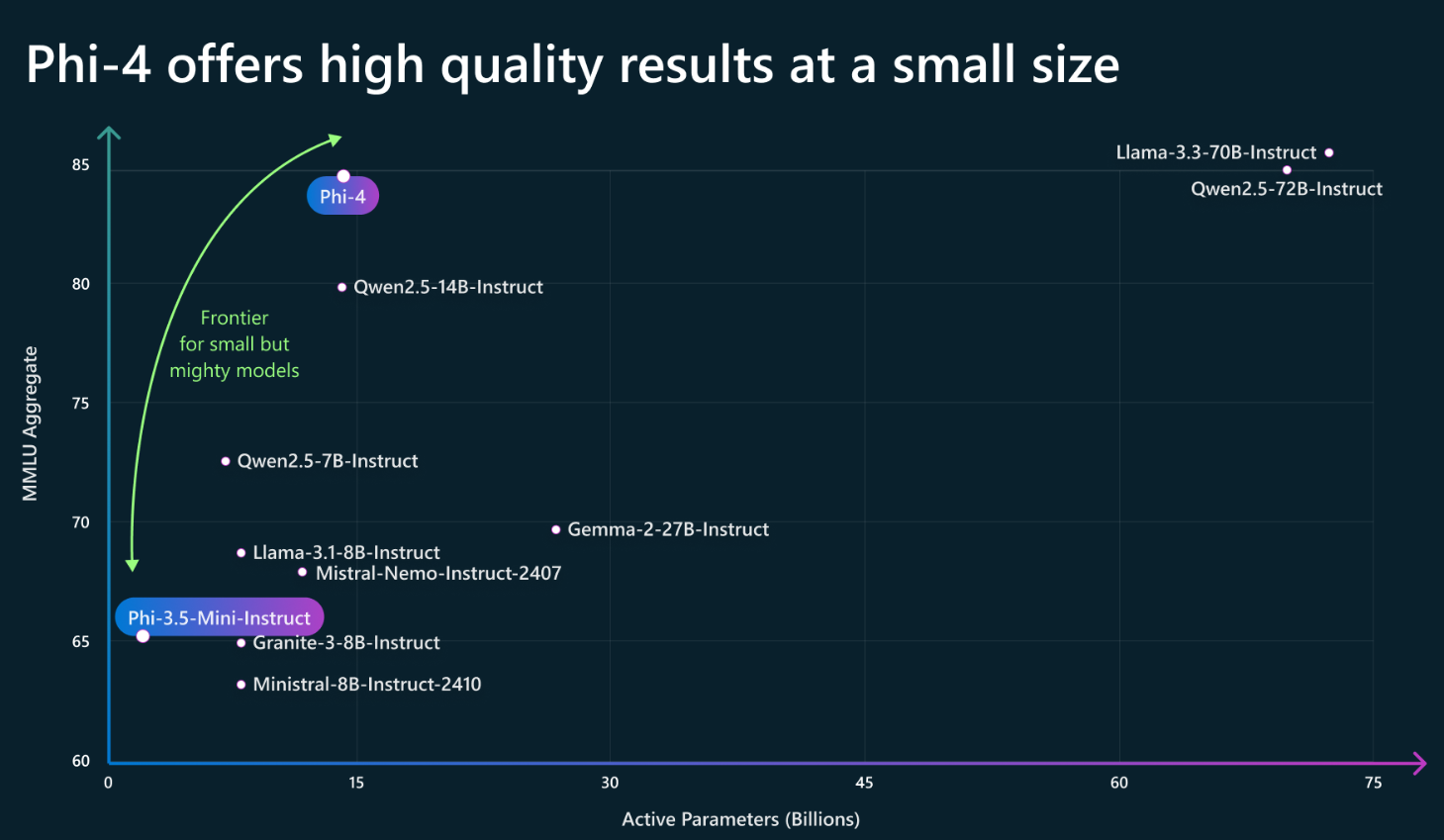
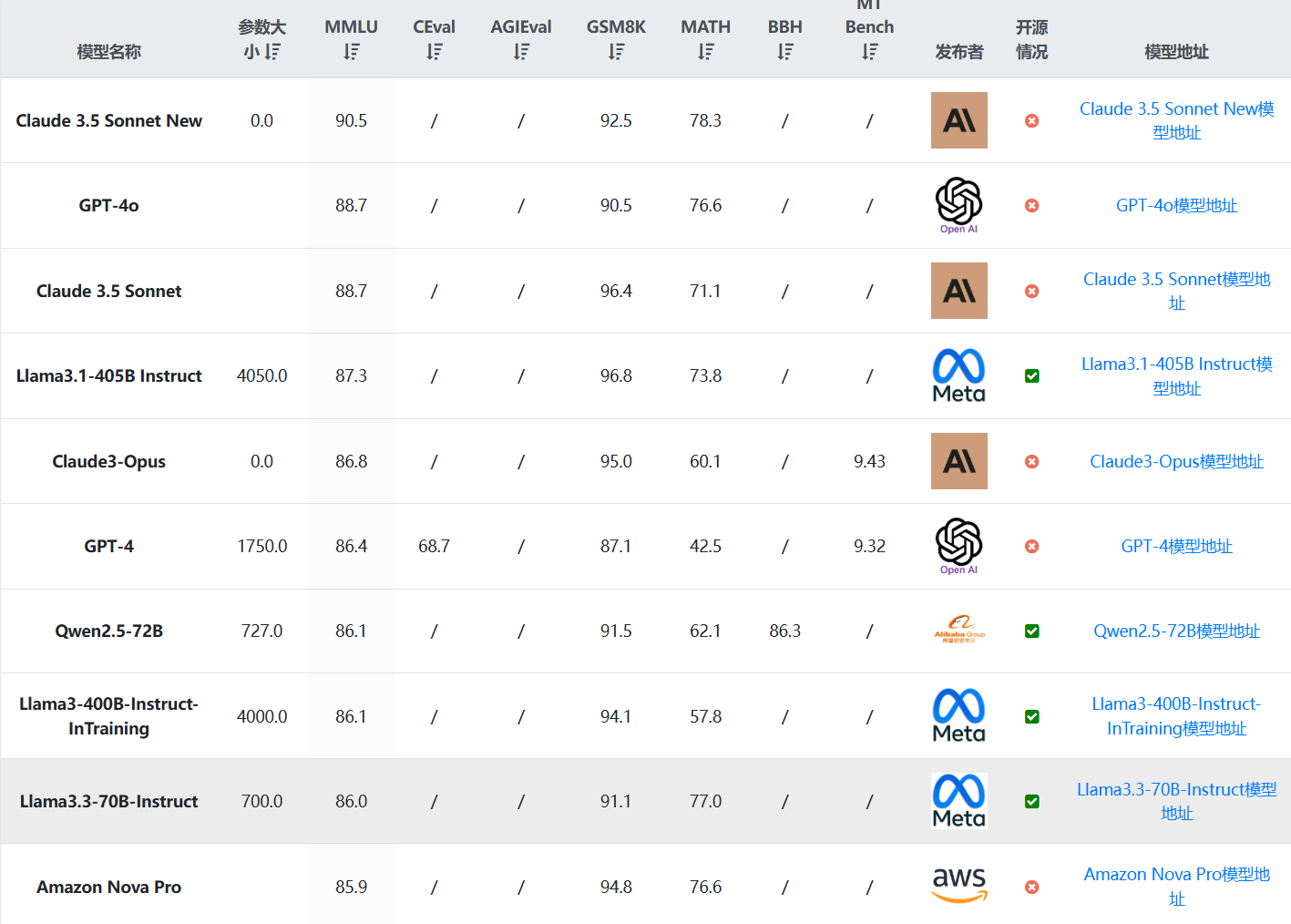
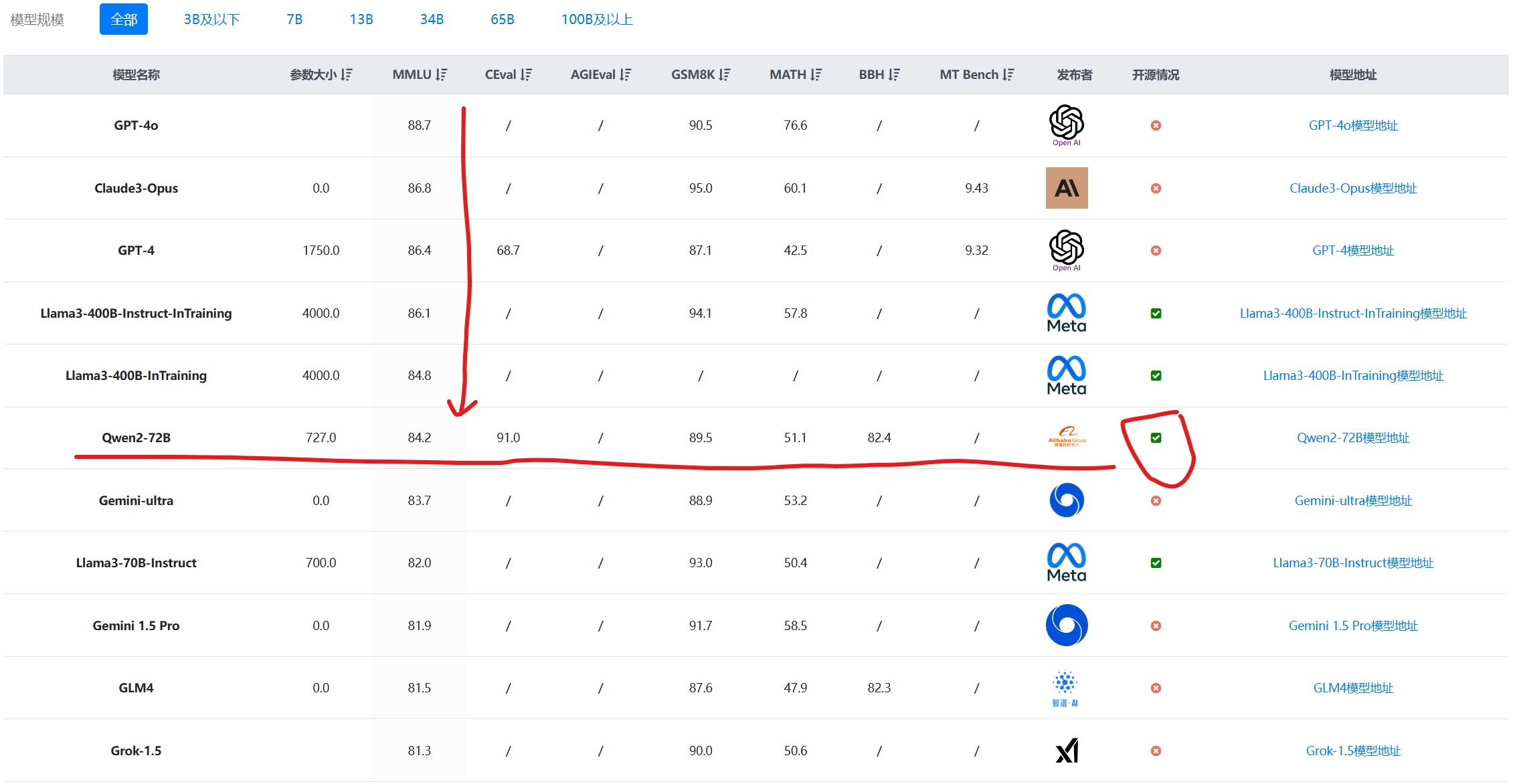
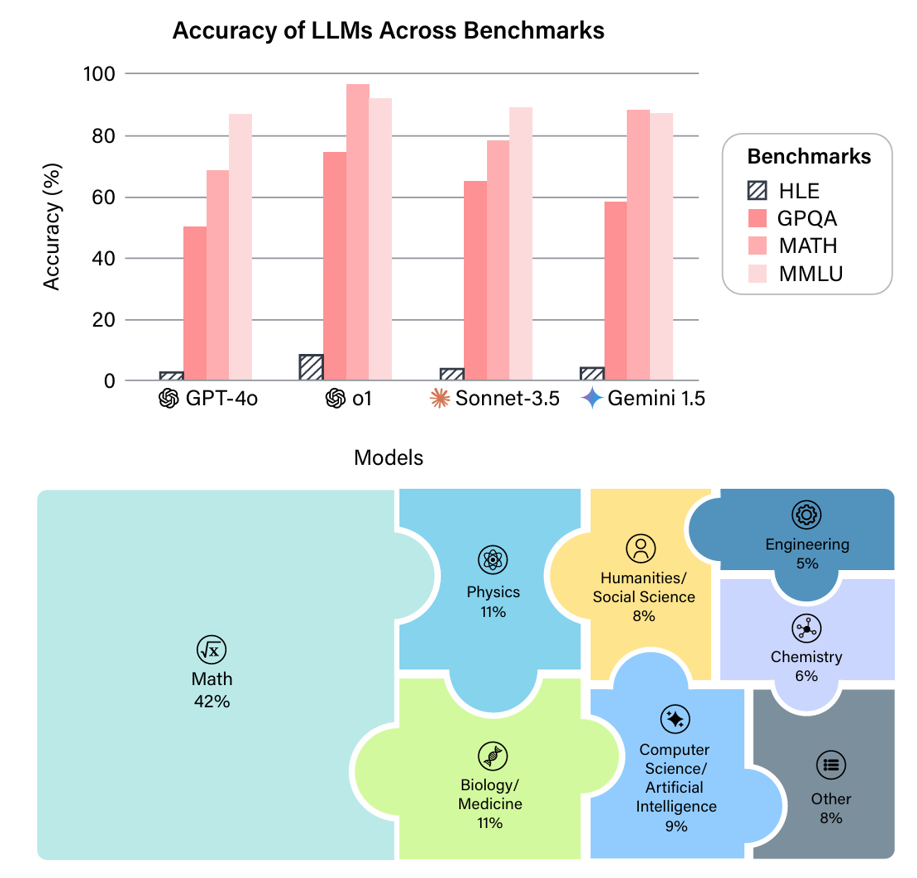
近年来,大语言模型(LLM)的能力飞速提升,但评测基准的发展却显得滞后。以广泛使用的MMLU(大规模多任务语言理解)为例,GPT-4、Claude等前沿模型已能在其90%以上的问题上取得高分。这种“评测饱和”现象导致研究者难以精准衡量模型在尖端知识领域的真实能力。为此,Safety for AI和Scale AI的研究人员推出了Humanity’s Last Exam大模型评测基准。这是一个全新的评测基准,旨在成为大模型“闭卷学术评测的终极考验”。