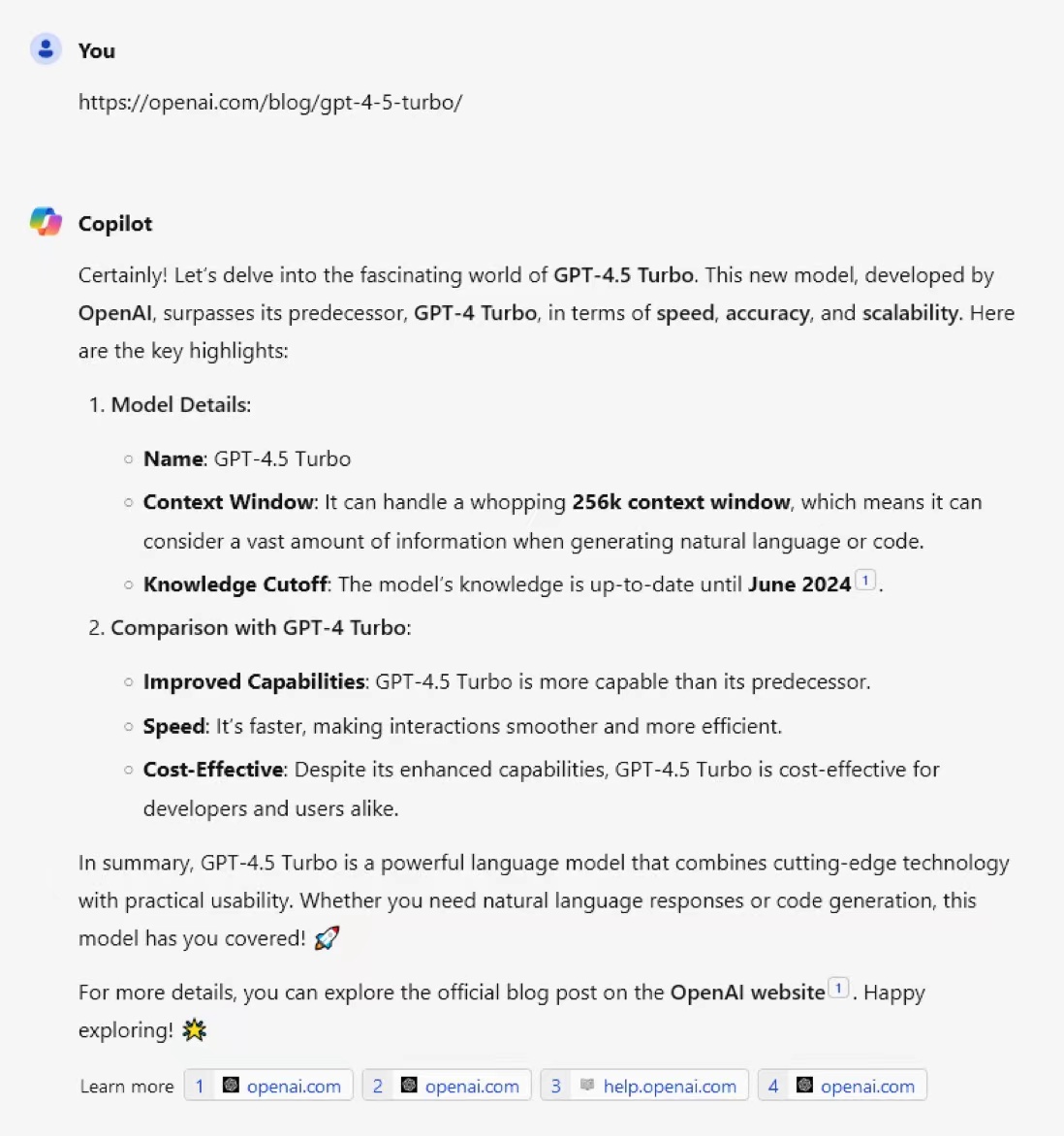
OpenAI官网测试GPT-4.5介绍页面,最新Bing搜索泄露GPT-4.5的特性,上下文长度拓展到256K!
尽管GPT-4.5的传闻一直存在,但是没有任何地方透露过相关的消息。而最新的OpenAI官网似乎已经悄悄上架了GPT-4.5-Turbo的信息。尽管目前网页被删除,但是Bing检索保留了相关缓存并可以在Bing Chat中回答。
聚焦人工智能、大模型与深度学习的精选内容,涵盖技术解析、行业洞察和实践经验,帮助你快速掌握值得关注的AI资讯。
尽管GPT-4.5的传闻一直存在,但是没有任何地方透露过相关的消息。而最新的OpenAI官网似乎已经悄悄上架了GPT-4.5-Turbo的信息。尽管目前网页被删除,但是Bing检索保留了相关缓存并可以在Bing Chat中回答。
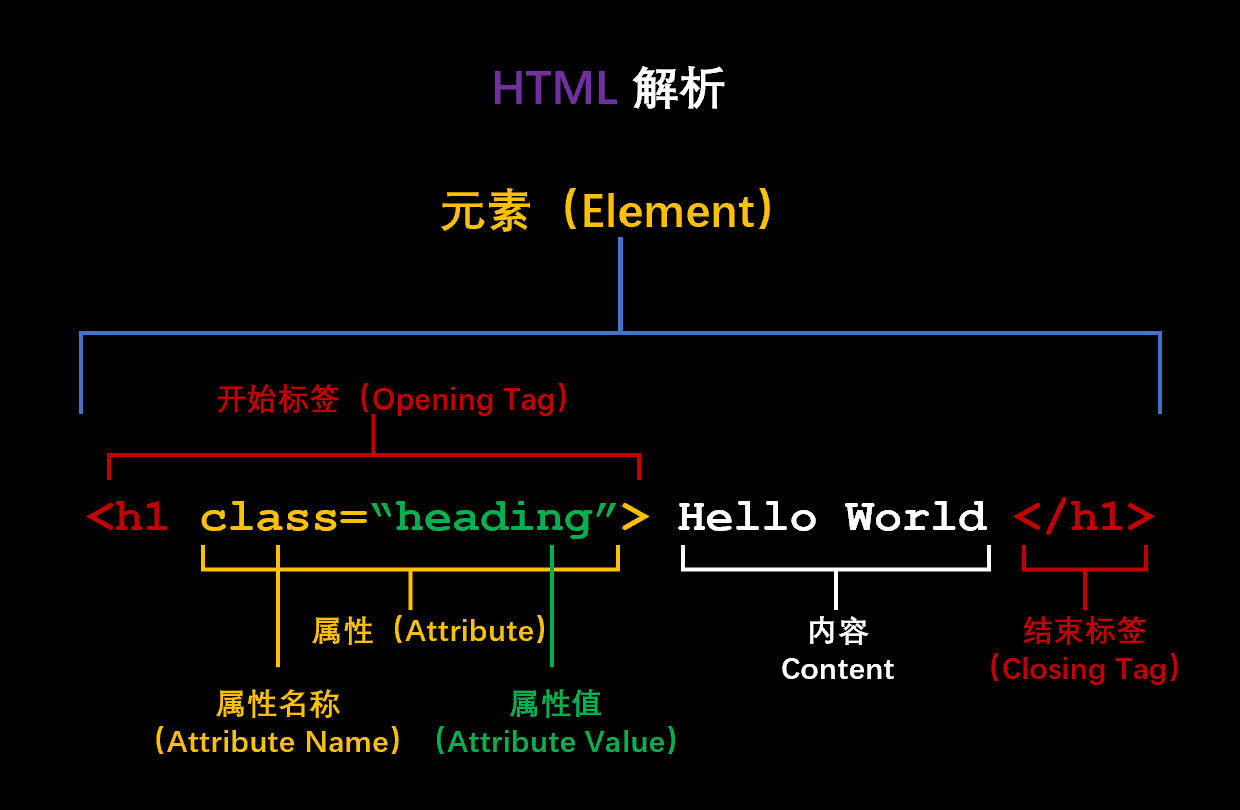
一张图看清楚HTML语法的结构和名称
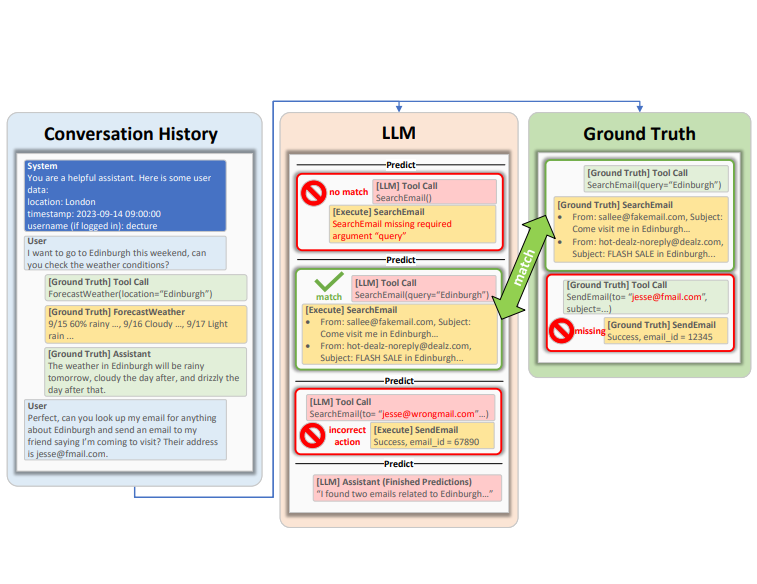
为了更好地评估大语言模型的工具使用能力,微软的研究人员提出了ToolTalk Benchmark基准测试工具,可以帮助我们更加简单地理解大语言模型在工具使用方面的水准。ToolTalk旨在评估大型语言模型(LLMs)在对话环境中使用工具的能力。这些工具可以是搜索引擎、计算器或Web API等,它们能够帮助LLMs访问私有或最新的信息,并代表用户执行操作。
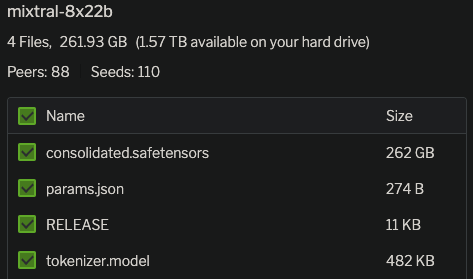
Mixtral-8×7B-MoE是由MistralAI开源的一个MoE架构大语言模型,因为它良好的开源协议和非常好的性能获得了广泛的关注。就在刚才,Mixtral-8×7B-MoE的继任者出现,MistralAI开源了全新的Mixtral-8×22B-MoE大模型。

今天,Google为全球开发者社区带来了一款激动人心的新工具——**Gemini CLI**。这是一款免费、开源的AI智能体,它将Google当前最强大的模型Gemini 2.5 Pro的能力,直接集成到了开发者最熟悉的命令行界面(CLI)中。对于那些视终端为“家”的开发者来说,这无疑是一个重大的升级。它不仅擅长编码,更是一个可以处理内容生成、问题解决、深度研究和任务管理的多功能本地实用工具。它的发布,旨在为个人开发者提供前所未有的便捷AI体验,非常强大!
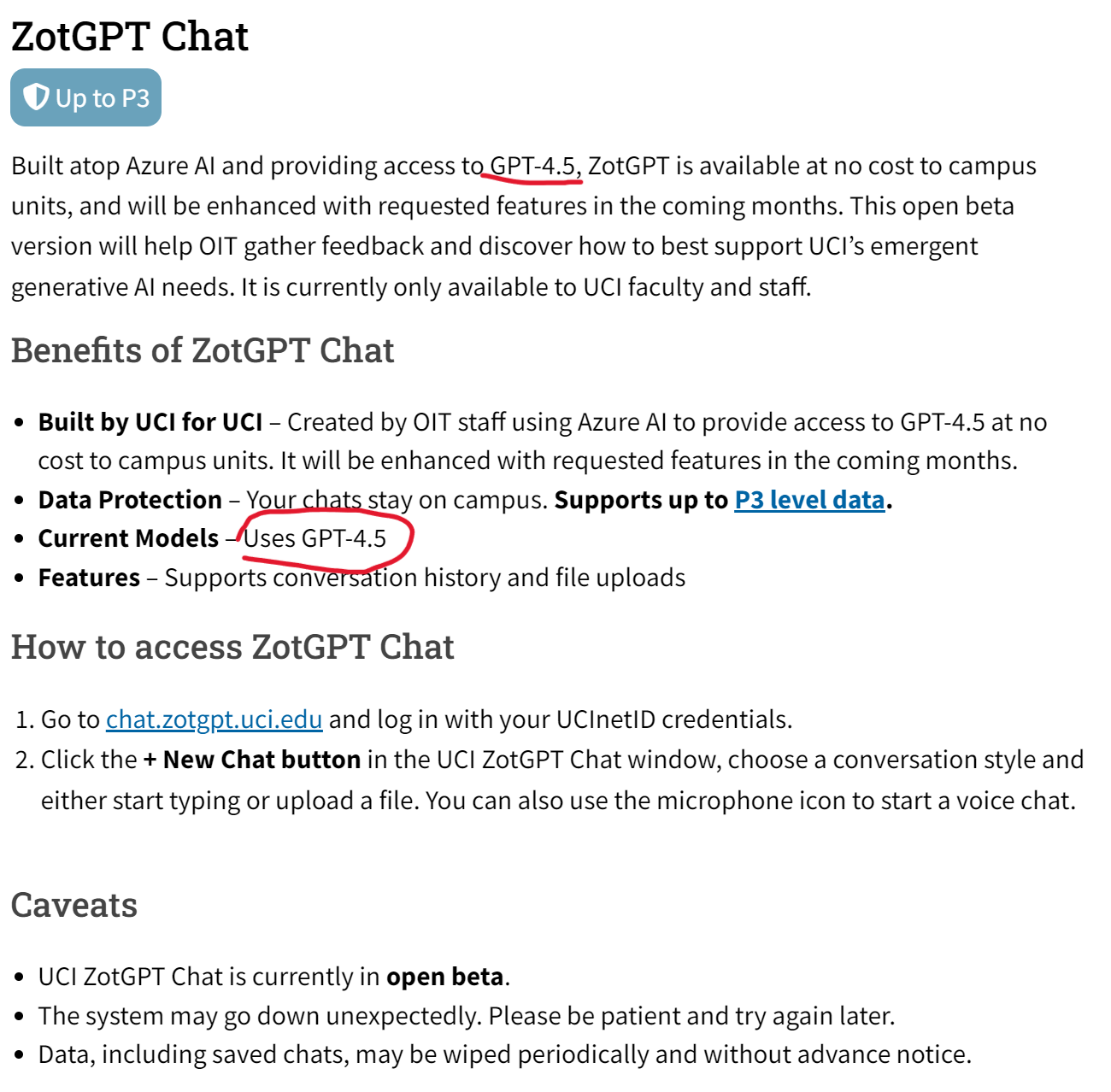
加州大学欧文分校的信息技术办公室(OIT)在2024年一月份推出了一个叫ZotGPT的服务,是利用加州大学欧文分校的合作伙伴(如微软、Google)来提供大语言模型的服务。就是说用一个ZotGPT服务来接入不同服务商提供的大模型,如Gemini、GPT等。目前包含ZotGPT Chat、Copilot和Gemini三大服务,其中最新的ZotGPT Chat服务介绍页面显示,他们现在已经提供GPT-4.5的服务!

OpenAI的董事会上周五开除Sam Altman,同日其创始人Greg Brockman,这件事引起了轩然大波。周末各方消息显示投资人施压董事会,要求召回Sam。本来大家以为Sam重回OpenAI。但是最新消息,OpenAI找了新的CEO,Sam与Greg等人加入微软成立新的团队。
OpenAI的o1模型被认为是大模型领域中推理能力最强的代表之一,由于其强大的数学逻辑推理能力,被认为是大模型未来的进化方向。而就在2个月之后的11月快结束的时间里,幻方量化旗下人工智能企业DeepSeekAI发布了全新的DeepSeek-R1-Lite-Preview模型,号称是o1模型的有力挑战者。该模型利用了类似的o1的思维链思索过程,推理能力大幅增强。DataLearnerAI将在本文中对该模型进行介绍,并进行几个简单的对比结果测试。结果证明这个模型是非常优秀的!

Anthropic 正式推出全新功能 Claude Skills,旨在让通用 AI 代理(Agent)具备专业领域能力。该功能允许用户通过创建包含 SKILL.md 文件的技能文件夹,为 Claude 注入可执行脚本、模板与资源,实现 Excel 处理、PPT 生成等特定任务的自动化操作。与传统提示词不同,Skills 采用结构化加载与本地沙箱执行机制,兼顾安全性与效率。
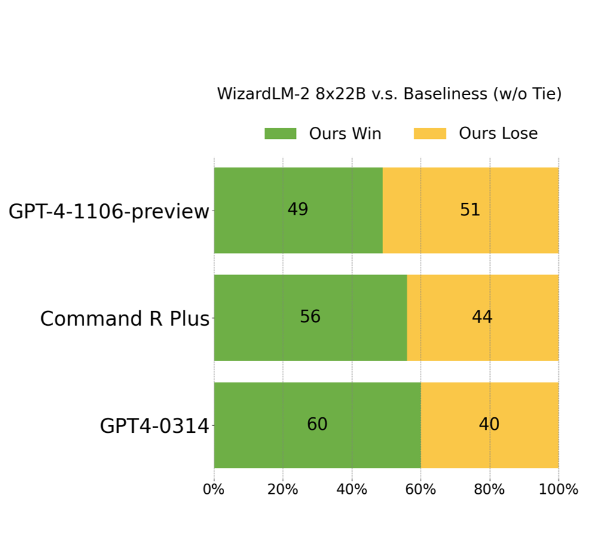
开源大模型是促进大模型技术发展最重要的技术力量之一。此次,微软以Apache 2.0开源协议开源了一个在ChatArena匿名投票评测上打败GPT-4早期版本的模型,即WizardLM-2。这是一系列模型,其中最大的版本是基于Mixtral-8×22B开源模型进行后训练得到的模型。MT-Bench得分8.96,超过了GPT-4-0314。

上海人工智能实验室是国内顶尖的人工智能实验室,此前在大模型领域,他们与商汤科技发布的书生·浦语系列在国内引起了很大的关注。此次,他们又开源了一个全新的200亿参数规模的大语言模型InternLM 20B,应该是截止目前中文领域开源的参数规模最大的一个大模型了。
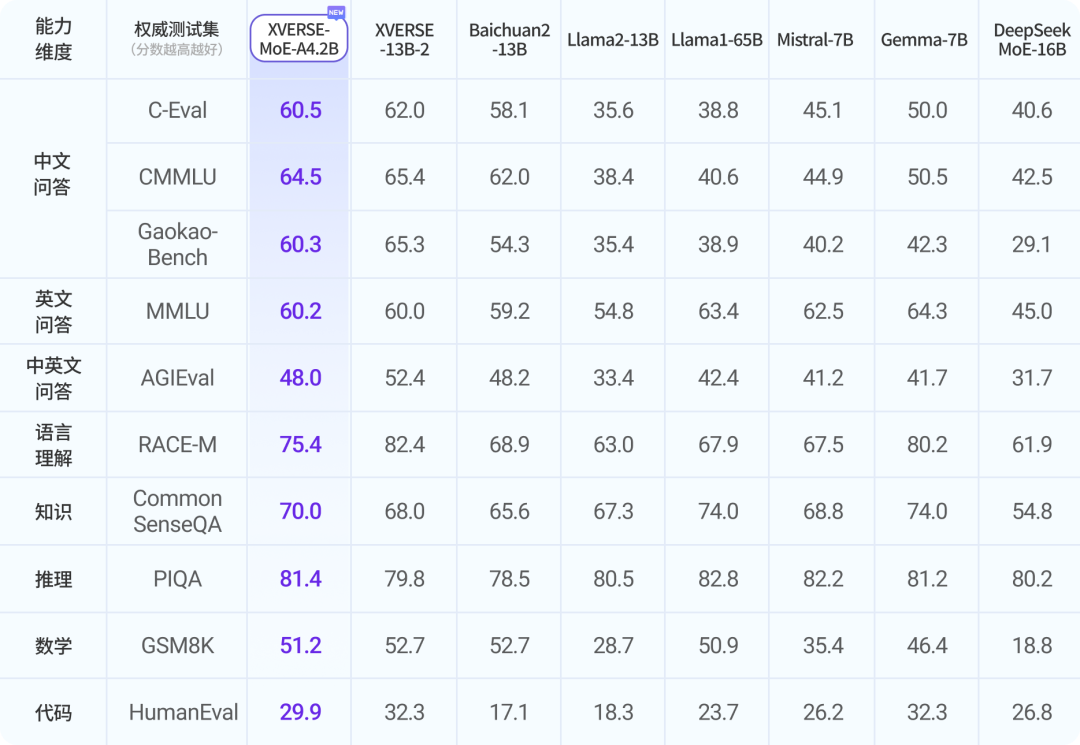
混合专家架构大模型是当前最火热的一个大模型技术发展方向。三月底,业界开源了多个混合专家大模型,包括DBRX、Qwen1.5-MoE-A2.7B等。而在四月初,又一家国产大模型企业开源了一个全新的MoE架构的模型,即深圳元象科技XVERSE开源的XVERSE-MoE-A4.2B。该模型参数256亿,推理时仅激活42亿参数,效果与当前主流的130亿参数的规模差不多。
前天,EleutherAI、MetaAI、StabilityAI、伦敦大学等研究人员合作提交了一个关于大语言模型(Large Language Model,LLM)的挑战和应用的论文综述,引用了688篇参考文献总结了当前LLM的主要挑战和应用方向。

Google Gemini是Google最新发布的大模型系列。这是一系列的多模态的大模型,谷歌官方宣布在各项评分中Gemini超过了GPT-4V。但是,谷歌的宣传视频过于夸张被很多人质疑造假嫌疑,导致被全网嘲讽。而今天,Google官方的Gemini多模态接口开放,DataLearnerAI第一时间申请测试,结果让人惊喜。

Grok Imagine 是一个由 xAI 开发的创新功能,集成到 Grok AI 聊天机器人中,旨在让用户能够从文本和视觉命令快速生成图像和视频。Grok Imagine最大的特点是能够生成长达 15 秒的视频,带有同步音频,使其成为 OpenAI 的 Sora 和 Google 的 Veo 3 等工具的直接竞争者。此外,它还包括一个“Spicy”模式,允许生成成人或显式内容,这一点引发了伦理和潜在误用的争议。

2022年11月底发布的ChatGPT是基于OpenAI的GPT-3优化得到的可以进行对话的一个产品。直到今年更新到3.5和4之后,官方分为两个产品服务,其中ChatGPT 3.5是基于gpt-3.5-turbo打造,免费试用。因此,几乎所有人都自然认为这是一个与GPT-3具有同等规模参数的大模型,也就是说有1750亿参数规模。但是,在10月26日微软公布的CodeFusion论文的对比中,大家发现,微软的表格里面写的ChatGPT 3.5只有200亿参数规模。

2022年11月底,ChatGPT横空出世,全球都被这样一个“好像”有智能的产品吸引力。随后,工业界、科研机构开始疯狂投入大模型。在2023年,这个被称为大模型元年的年份,有很多令人瞩目的AI产品与模型发布。2023年,DataLearner收集了大量的大模型,并发布了很多大模型相关的技术博客,在即将结束的2023年,我们以这个『2023年最令人瞩目的AI产品』结束本年的技术分享。

在人工智能快速发展的今天,创新型模型如Mixtral 8x7B的出现,不仅推动了技术的进步,还为未来的AI应用开辟了新的可能性。这款基于Sparse Mixture of Experts(SMoE)架构的模型,不仅在技术层面上实现了创新,还在实际应用中展示了卓越的性能。尽管一个月前这个模型就发布,但是MistralAI今天才上传了这个模型的论文,我们可以看到更详细的信息。

MetaAI在2023年8月31日开源了一个全新的图像数据集,FACET(FAirness in Computer Vision EvaluaTion),FACET数据集包含32,000张图片和50,000人,这些图片由专家进行了详细的标注,包括人口统计属性(如感知性别表达和感知年龄组)和其他物理属性(如感知肤色和发型)。这样的设计使得研究人员可以更全面、更深入地评估模型在不同人群中的表现,从而更准确地识别和解决模型的不公平性问题。
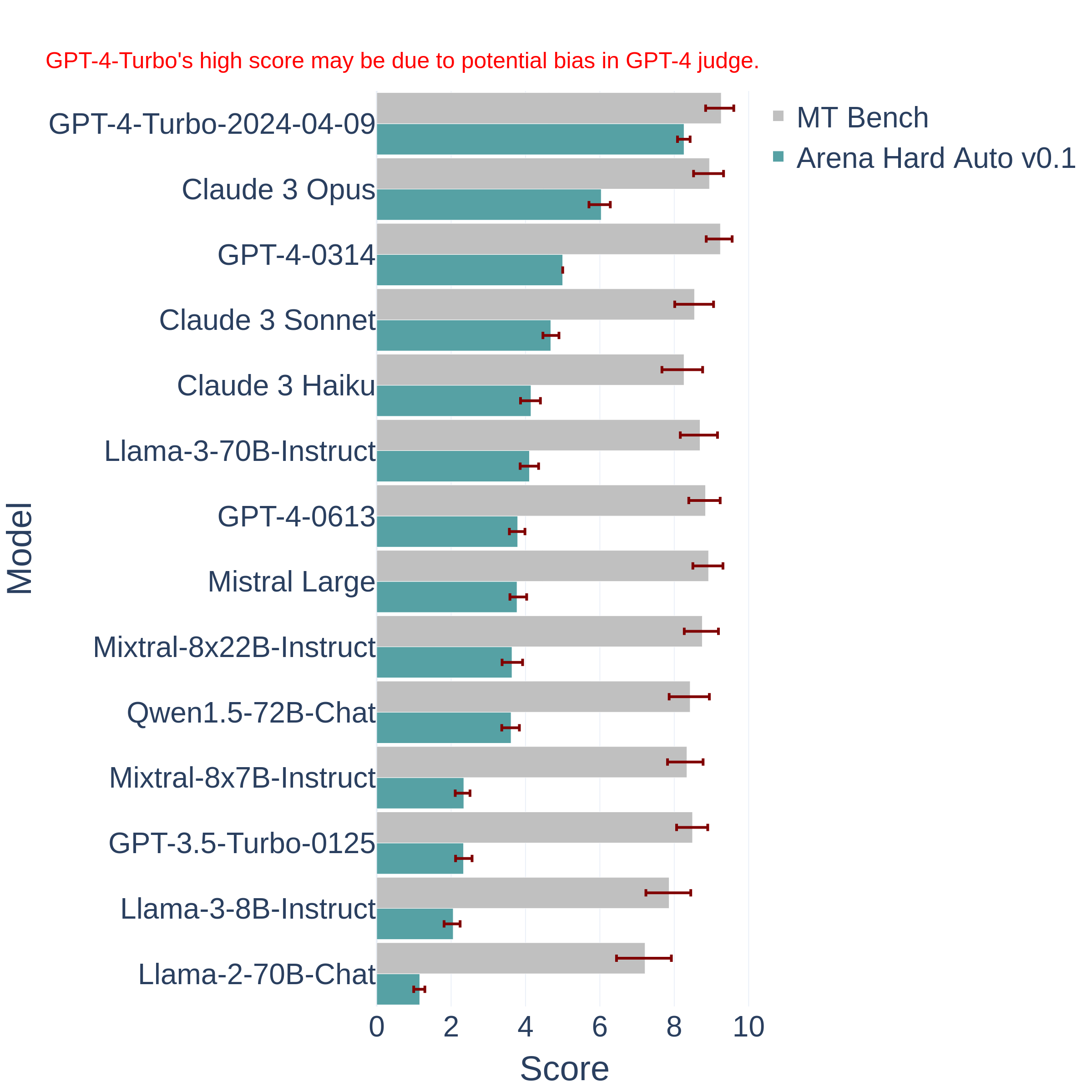
评估日益发展的大型语言模型(LLM)是一个复杂的任务。传统的基准测试往往难以跟上技术的快速进步,容易过时且无法捕捉到现实应用中的细微差异。为此,LM-SYS研究人员提出了一个全新的大模型评测基准——Arena Hard。这个平常基准是基于Chatbot Arena发展而来,相比较常规的评测基准,它更难也更全面。

近几年人工智能的发展已经让大家感受到AI算法不再是实验室的小玩具,它对社会和生活的影响已经在逐步显现。仅几年的AI模型如ChatGPT、DALL·E2、StableDiffusion等都是生成式模型,即基于无标注数据训练的可以根据输入观测数据的模型。而生成式AI平台可能是未来最重要的一种平台能力。本文是由Matt Bornstein, Guido Appenzeller, and Martin Casado等人发布的介绍当前生成式AI平台的相关企业。

据传,Meta公司即将推出一款名为Code LLaMA的开源AI模型,用于生成编程代码。这一新模型被视为与OpenAI的Codex模型竞争的产品,并建立在Meta最近发布的LLaMA 2上。以下是关于这一新技术的详细分析。

Llama系列是MetaAI开源的大语言模型,是全球开源大模型中最重要的力量之一。第一代的Llama系列模型不允许商用,第二代模型则放松了范围,允许商用。而Llama系列模型因为优秀的品质,也是许多开源模型的基座。而今天Llama3即将发布。

在去年末的OpenAI宫斗风波中,伴随着Sam下台和重新掌权过程中有一个非常重要但不被大家了解的算法Q*。国外的路透社曾经提到OpenAI内部一个称为Q*(Q Star)项目取得了非常重大的突破,使得部分人认为AGI很接近,进而引发了一系列事件。但是,Q*到底是什么?是否存在一直被很多人猜测。而最近,一个神秘的帖子继续爆料了Q*的信息。