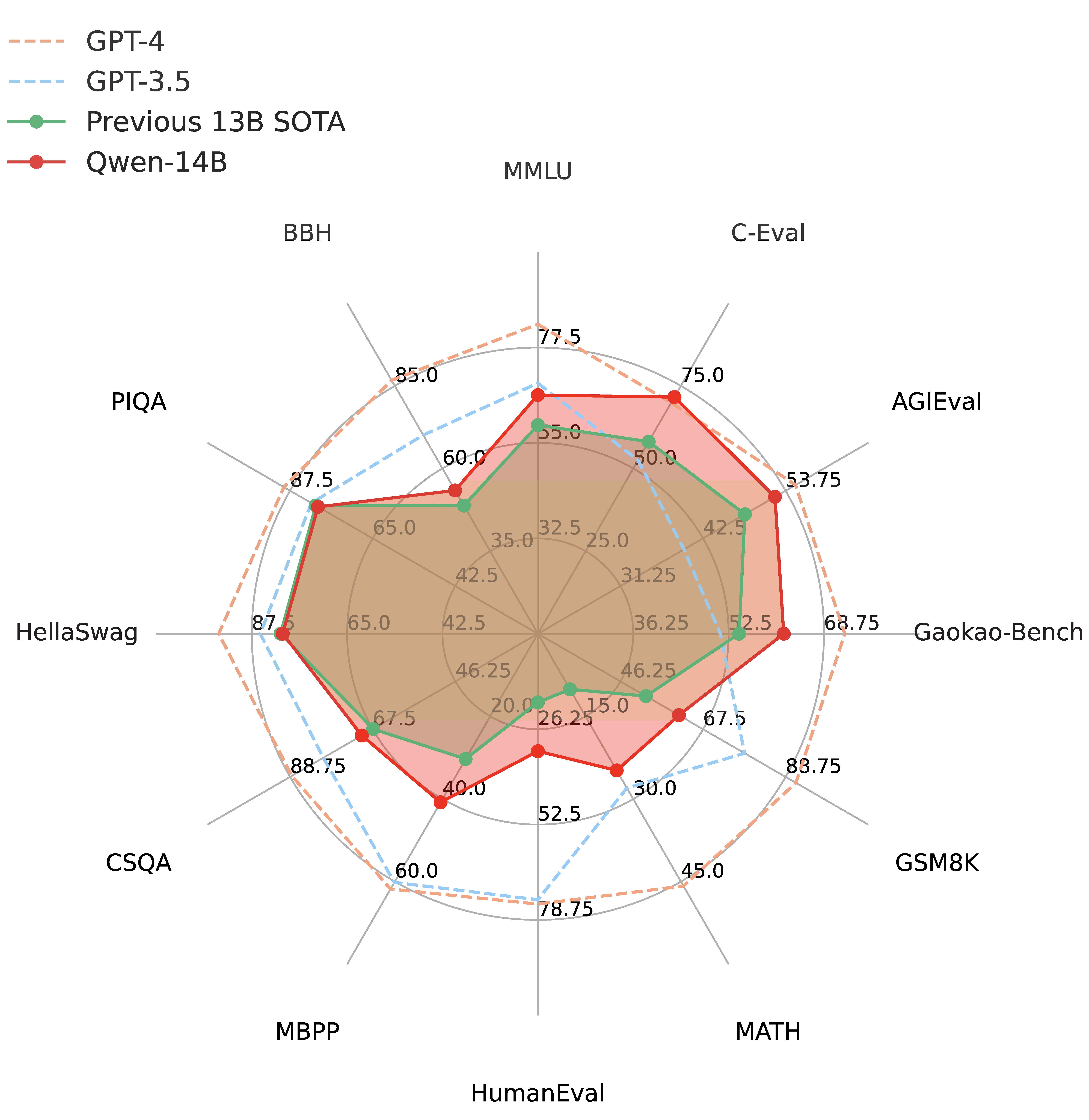
阿里开源最新Qwen-14B:英文理解能力接近LLaMA2-70B,数学推理能力超过GPT-3.5!
通义千问是阿里巴巴推出的一个大语言模型,此前开源的Qwen-7B引起了广泛的关注,因为他的理解能力很强但是参数规模很小,因此受到了很多人的欢迎。而目前再次开源全新的Qwen-14B的模型,参数规模142亿,但是它的理解能力接近700亿参数规模的LLaMA2-70B,数学推理能力超过GPT-3.5。
探索人工智能与大模型最新资讯与技术博客,涵盖机器学习、深度学习、自然语言处理等领域的原创技术文章与实践案例。
通义千问是阿里巴巴推出的一个大语言模型,此前开源的Qwen-7B引起了广泛的关注,因为他的理解能力很强但是参数规模很小,因此受到了很多人的欢迎。而目前再次开源全新的Qwen-14B的模型,参数规模142亿,但是它的理解能力接近700亿参数规模的LLaMA2-70B,数学推理能力超过GPT-3.5。

大模型的发展一个重要的基础条件是底层硬件计算能力的大幅提高,特别是GPU的发展,与transformer架构的大模型训练非常契合。当前全球最大的GPU供应商英伟达系列的显卡几乎垄断了大模型训练与推理的所有GPU芯片市场。除了英伟达显卡本身算力强悍外,基于英伟达GPU之上构建的CUDA、PyTorch等平台软件生态也是非常重要的一环。而最新的PyTorch2.1版本发布的一个beta特性中包含了对华为昇腾芯片的原生支持,这也是大模型生态多样性发展的一个很重要的信号。
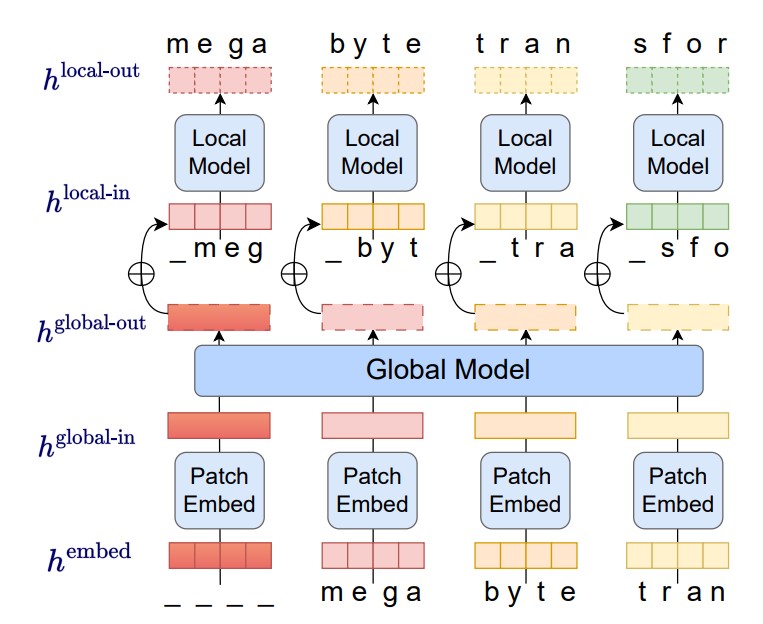
尽管OpenAI的ChatGPT很火爆,但是这类大语言模型有一个非常严重的问题就是对输入的内容长度有着很大的限制。例如,ChatGPT-3.5的输入限制是4096个tokens。MetaAI在前几天提交了一个论文,提出了MegaByte方法,几乎可以让模型接受任意长度的限制!

在大语言模型中,上下文长度是指模型可以考虑的输入数据的数量。更长的上下文在大语言模型的实际应用中有非常重要的价值。当前,让大语言模型支持更长的上下文有两种常用的方法,一种是训练支持更长上下文长度的模型,扩展模型的输入,另外一种是检索增强生成的方法(Retrieval Augmentation Generation,RAG)。但二者应该如何选择,这是一个很少能直接比较的问题。为此,英伟达(Nvidia)的研究人员做了一个详细的比较。

大模型应用中一个非常重要的问题就是大模型的响应速度。尤其是作为聊天应用来说,在用户输入之后,大模型可以在多短的时间内给出回应对于用户体验来说影响巨大。这里有2个问题经常会被大家所关注,一个是大模型每秒输出多少个tokens就可以满足用户的日常聊天使用,另一个问题是单张显卡最多可以支撑多少个用户的聊天需求。在前几天的vllm meetup上,贾扬清给出了一些讨论,他认为我们目前可能高估了大模型的聊天应用成本。
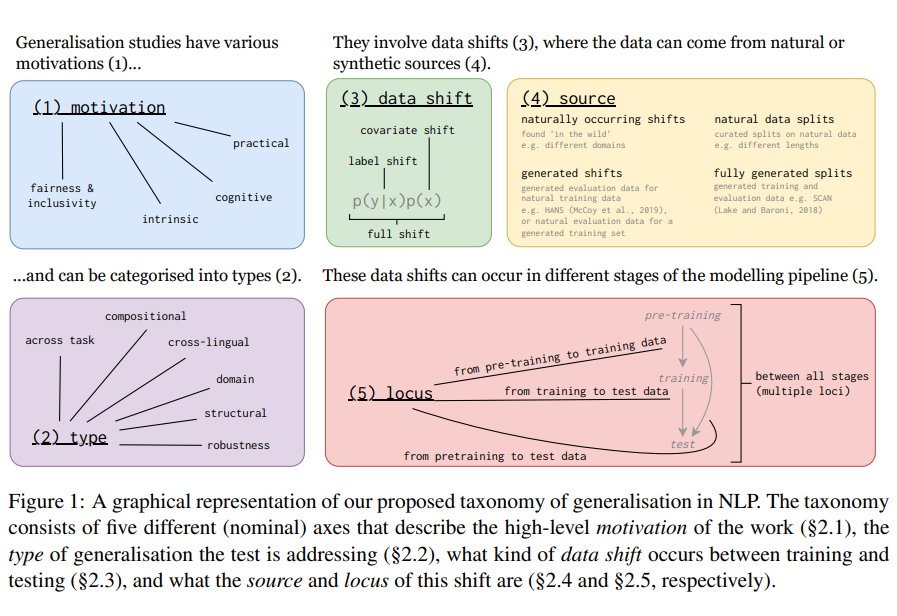
关于什么是好的泛化、存在哪些类型的泛化以及在不同的场景中哪些应该被优先考虑,人们对此了解甚少且意见不一。而MetaAI等机构的研究人员最近发布了一篇关于大模型泛化能力的综述,详细总结了大模型泛化能力的分类等。本篇论文详细总结一下大模型的泛化能力分类以及什么样的泛化是未来的中的重点等问题。
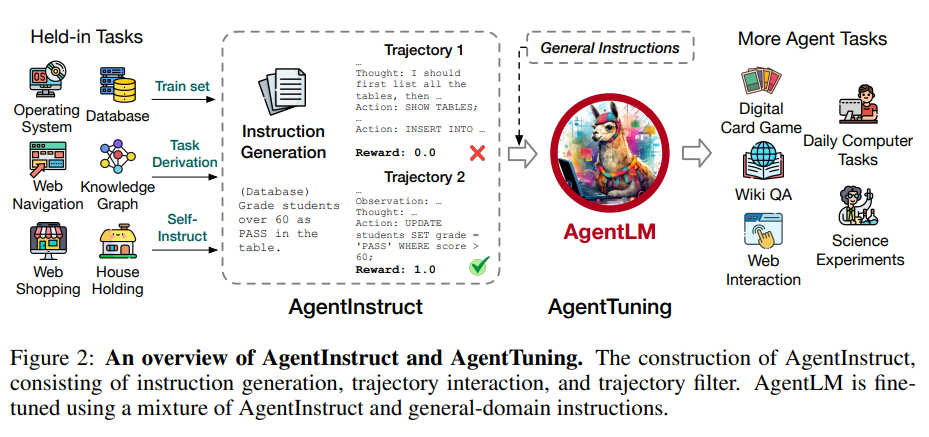
尽管开源的大语言模型发展非常迅速,但是,在以大语言模型作为核心的新一代AI Agent解决方案上,开源大语言模型比商业模型表现要明显地差。为了提高大语言模型作为AI Agent的表现和能力,清华大学和智谱AI推出了一种新的方案,AgentTuning,可以将有效增强开源大语言模型作为AI Agent的能力。
Sebastian Raschka博士是一位深度学习和人工智能研究员、程序员、作者和教育者。他曾是威斯康星大学麦迪逊分校的统计学助理教授,专注于机器学习和深度学习研究。然而,他在2023年辞职,全职投入到他在2022年加入的Lightning AI创业公司,担任首席AI教育者。本文是Sebastian Raschka博士最新的2023年AI进展总结的翻译,大家参考。

检索增强生成(Retrieval-augmented Generation,RAG)可以让大语言模型与最新的外部数据或者知识连接,进而可以基于最新的知识和数据回答问题。尽管检索增强生成是一种很好的补充方法,如果文档切分有问题、检索不准确,结果也是不好的。而检索增强生成也有一些提升方法,本文基于LangChain提供的一些方法给大家总结一下。

检索增强生成(Retrieval-augmented Generation,RAG)是一种结合了检索和大模型生成的方法。它从一个大型知识库中检索与输入相关的信息,然后利用这些信息作为上下文和问题一起输入给大语言模型,并让大语言模型基于这些信息生成答案的方式。检索增强生成可以让大语言模型与最新的外部数据或者知识连接,进而可以基于最新的知识和数据回答问题。尽管检索增强生成是一种很好的补充方法,但是,如果文档切分有问题、检索不准确,结果也是不好的。
ChatGLM系列是智谱AI发布的一系列大语言模型,因为其优秀的性能和良好的开源协议,在国产大模型和全球大模型领域都有很高的知名度。今天,智谱AI开源其第三代基座大语言模型ChatGLM3-6B,官方说明该模型的性能较前一代大幅提升,是10B以下最强基础大模型!
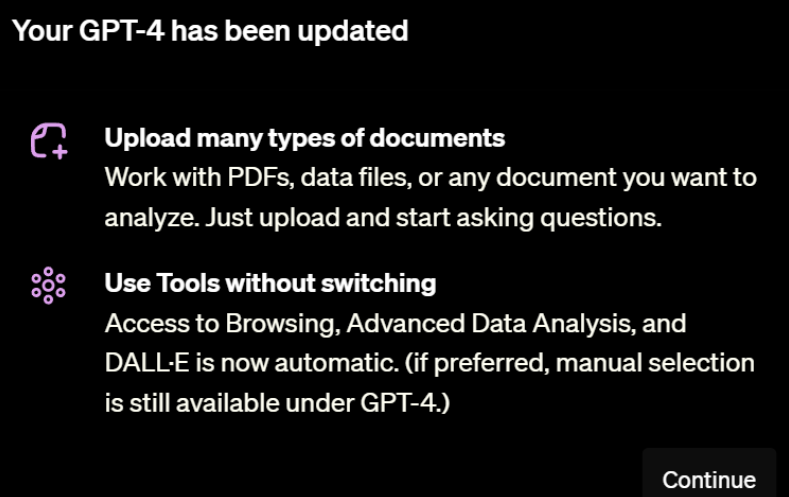
此前OpenAI的ChatGPT Plus版本为GPT-4模型提供了多个强大的插件供大家使用,包括基于Bing的带网络浏览的Browse、文本生成图片的DALL·E3、高级数据分析功能等。就在几个小时前,OpenAI的部分用户收到了官方的一个非常重磅的更新,即上传任意文档的分析以及整合了所有工具后的GPT-4!这个功能被称为GPT-4(All Tools)!这个工具可以在一次对话中自主选择调用多个不同工具完成用户的输入指令,非常接近AI Agent形态!

在大语言模型的训练和应用中,计算精度是一个非常重要的概念,本文将详细解释关于大语言模型中FP32、FP16等精度概念,并说明为什么大语言模型的训练通常使用FP32精度。

2022年11月底发布的ChatGPT是基于OpenAI的GPT-3优化得到的可以进行对话的一个产品。直到今年更新到3.5和4之后,官方分为两个产品服务,其中ChatGPT 3.5是基于gpt-3.5-turbo打造,免费试用。因此,几乎所有人都自然认为这是一个与GPT-3具有同等规模参数的大模型,也就是说有1750亿参数规模。但是,在10月26日微软公布的CodeFusion论文的对比中,大家发现,微软的表格里面写的ChatGPT 3.5只有200亿参数规模。

M3系列芯片是苹果最新发布的芯片。也是当前苹果性能最好的芯片。由于苹果的统一内存架构以及它的超大内存,此前很多人发现可以使用苹果的电脑来运行大语言模型。尽管它的运行速度不如英伟达最先进的显卡,但是由于超大的内存(显存),它可以载入非常大规模的模型。而此次的M3芯片效果如何,本文做一个简单的分析。
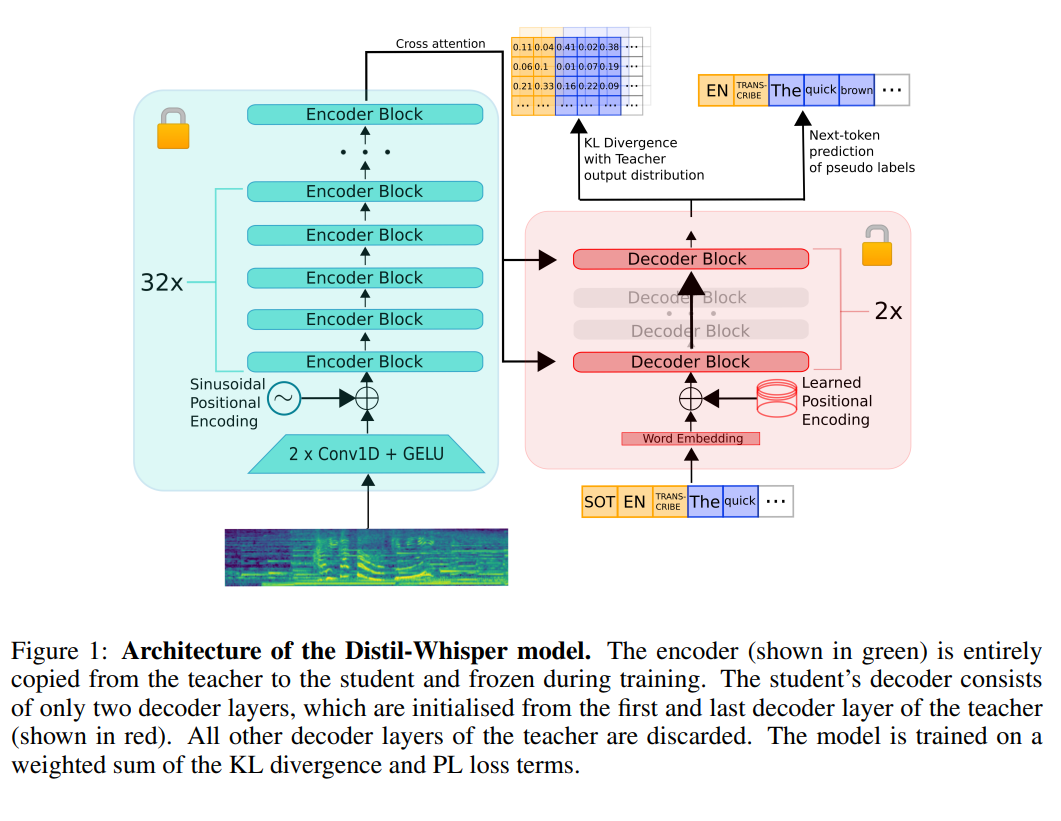
语音识别在实际应用中有非常多的应用。早先,OpenAI发布的Whisper模型是目前语音识别模型中最受关注的一类,也很可能是目前ChatGPT客户端语音识别背后的模型。HuggingFace基于Whisper训练并开源了一个全新的Distil-Whisper,它比Whisper-v2速度快6倍,参数小49%,而实际效果几乎没有区别。

ChatGPT是OpenAI提供的最强大的大模型服务。而截止目前为止,OpenAI公开的ChatGPT的订阅计划包含三个:免费版本的ChatGPT-3.5、个人用户付费订阅的ChatGPT Plus以及面向企业的企业版本。而最新的ChatGPT的API接口显示,OpenAI即将推出一个Team版本的计划,是当前ChatGPT Plus版本的升级版!
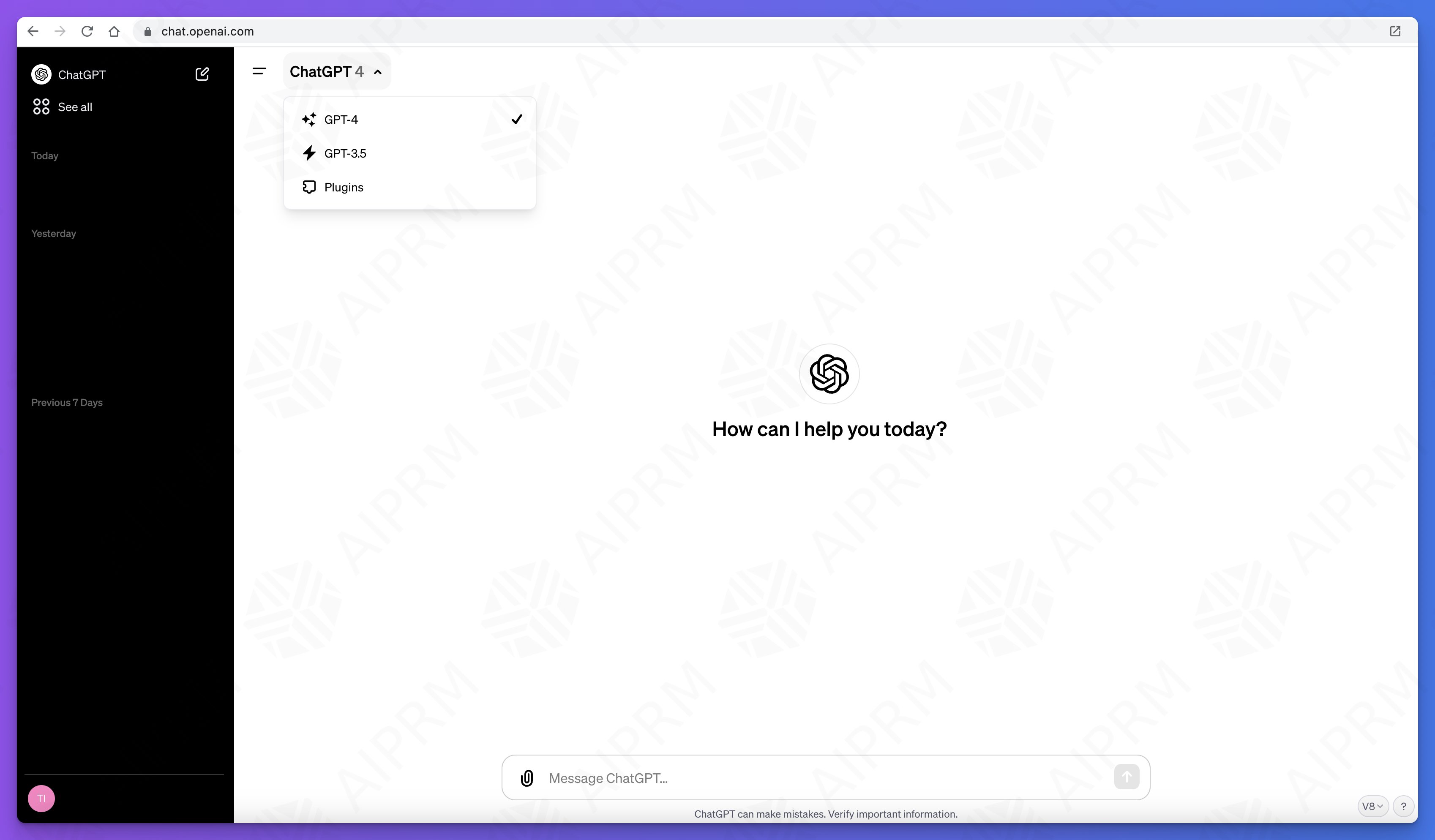
ChatGPT是当前大模型服务最前沿和风向标,每一次改动都会引起巨大的关注。此前,在ChatGPT的js脚本中就隐藏了即将发布的ChatGPT Team计划。而现在,新的ChatGPT UI代码和功能也被发现。新的GPT除了界面的巨大变化外,还有一个类似自定义AI Agent能力,可以直接接入自己的私有数据和API接口对外提供服务!十分震惊!
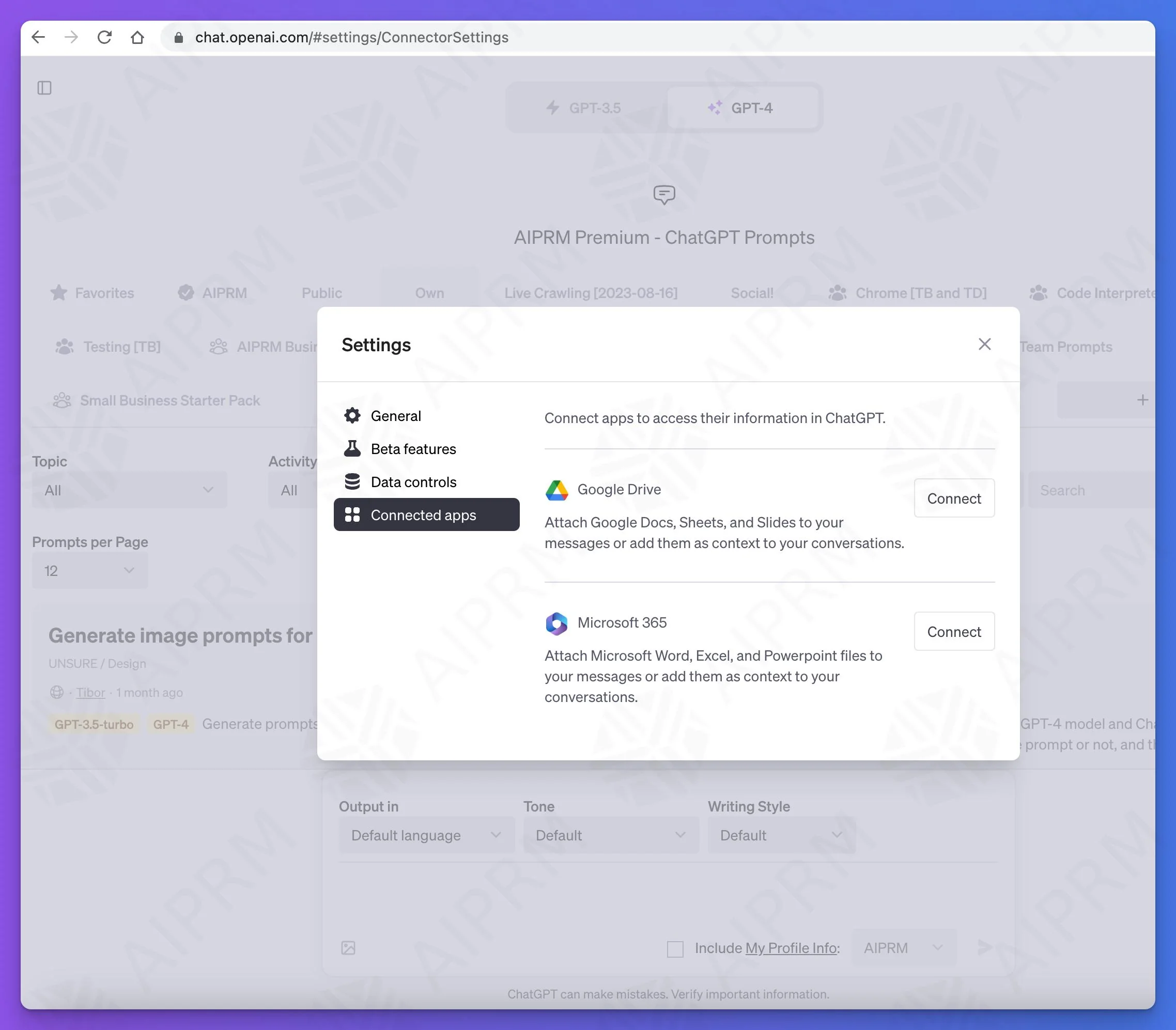
ChatGPT的发展速度很快,在前面已经介绍过ChatGPT即将推出的Team订阅计划和新界面,包括对接自定义数据和自定义接口等。此外,DataLearnerAI还发现ChatGPT即将推出关联APP的能力,截图显示,目前已经测试了对接Google Drive和Microsoft 365两个。

xAI是马斯克在2023年3月份创办的一家大模型初创企业。因为ChatGPT过于火爆,离开OpenAI之后马斯克又再次开始推出大模型,就是这个Grok。xAI今天也宣布了Grok模型的细节。其在多个知名榜单评测上的得分结果超过了ChatGPT-3.5水平。本文详细介绍一下这个模型。

尽管OpenAI最早也是马斯克和别人一起创立,由于各种原因分道扬镳之后马斯克也没有对相关产品感兴趣,直到ChatGPT风卷全球之后,马斯克与OpenAI的人公开吵了几次之后成立了这家公司。半年后的现在,马斯克透露xAI即将发布它的首个大模型Grōk AI。而一位老哥已经透露了该模型的一些细节。

最近很多ChatGPT Plus用户发现GPT-4的版本有了较大的更新,一个比较吸引人的事情是大多数更新后的GPT-4的知识库已经更新到2023年4月份,而且响应速度大幅提高。不过,令人伤心的是,很多用户发现更新后的GPT-4性能大幅下降,表现在指令遵从、记忆、理解等方面。

国产大语言模型的开源领域一直是很多企业或者科研机构都在卷的领域。最早,智谱AI开源ChatGLM-6B之后,国产大模型的开源就开始不断发展。早期大模型开源的参数规模一直在60-70亿参数规模,随着后续阿里千问系列的140亿参数的模型开源以及智源340亿参数模型开源之后,元象科技开源650亿参数规模的大语言模型XVERSE-65B,将国产开源大模型的参数规模提高到新的台阶。
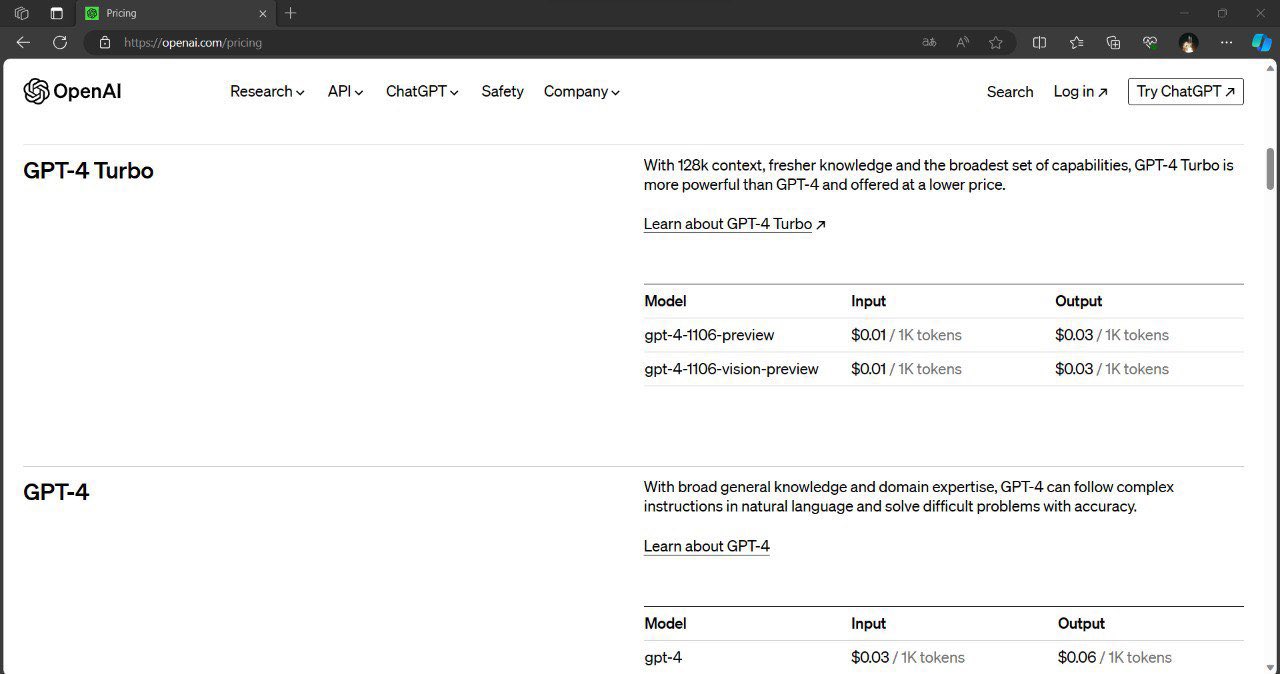
就在刚刚,有网友发现OpenAI的官方的文档接口更新中增加了128K的超长上下文版本,命名为GPT-4-128K-Turbo!