阿里正式开源最强视觉理解大模型Qwen3-VL:关键评测基准超Gemini 2.5 Pro,支持针对视觉输入进行推理,甚至可以理解3D场景
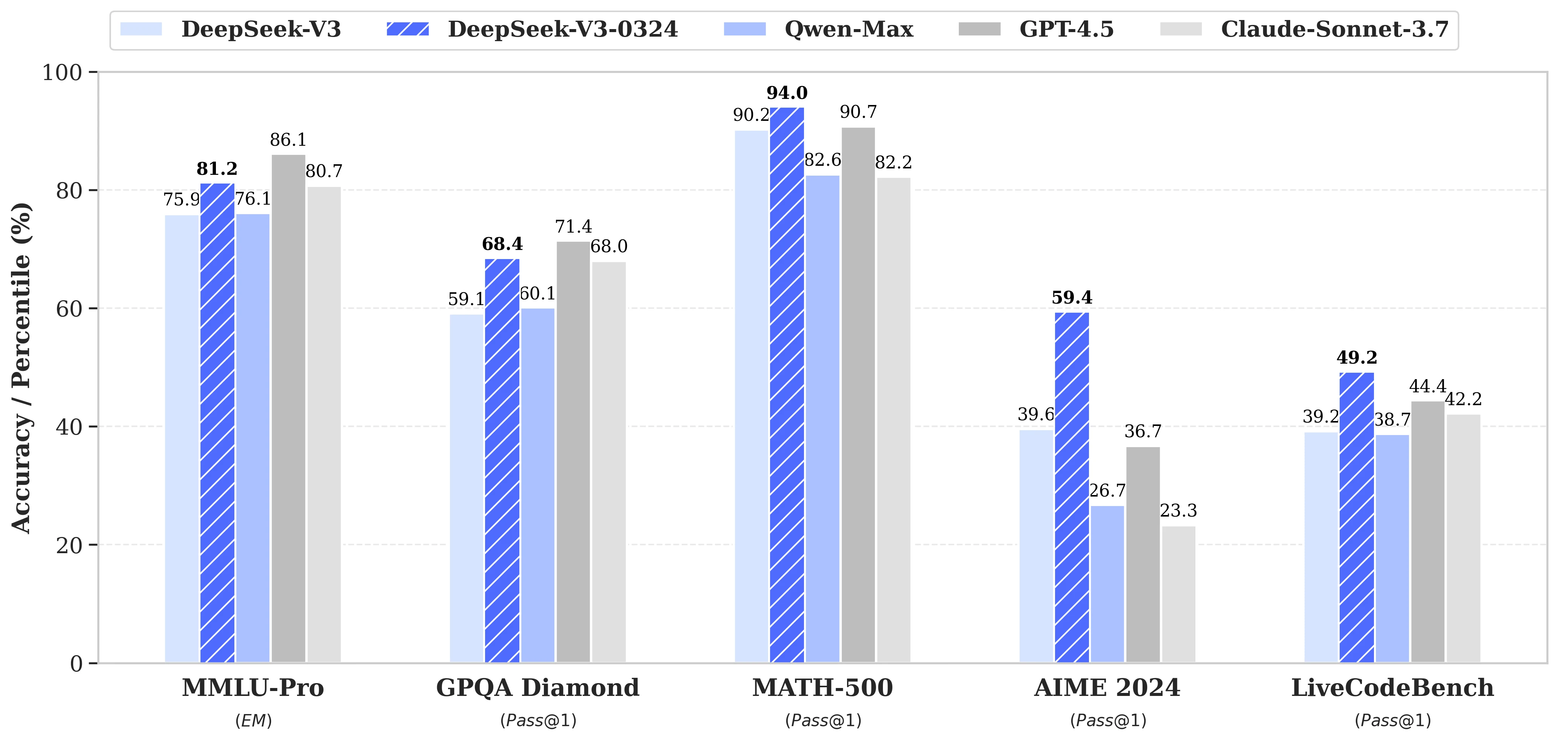
今日,QwenTeam 正式发布了全新一代多模态视觉语言模型 —— Qwen3-VL 系列。这是 Qwen 家族迄今为止最强大的视觉语言模型,在视觉感知、跨模态推理、长上下文理解、空间推理和智能代理交互等多个维度全面提升。旗舰开源模型 Qwen3-VL-235B-A22B 已经上线,并提供 Instruct 和 Thinking 两个版本,前者在视觉感知上全面对标并超过 Gemini 2.5 Pro,后者则在多模态推理基准上创下新纪录,成为开源阵营的最强视觉理解大模型。