
直接使用大模型通过界面来操作电脑和浏览器:谷歌发布Gemini 2.5 Computer Use 模型,重塑 AI 与界面交互能力,实测优秀~
就在昨天,2025年10月7日,Google DeepMind 正式发布其最新模型——Gemini 2.5 Computer Use。该模型基于 Gemini 2.5 Pro 的视觉理解与推理能力,新增了“界面交互(UI 控制)”能力,能够在浏览器或移动端界面上像人类那样点击、输入、滚动、选择控件等操作。
探索人工智能与大模型最新资讯与技术博客,涵盖机器学习、深度学习、自然语言处理等领域的原创技术文章与实践案例。
就在昨天,2025年10月7日,Google DeepMind 正式发布其最新模型——Gemini 2.5 Computer Use。该模型基于 Gemini 2.5 Pro 的视觉理解与推理能力,新增了“界面交互(UI 控制)”能力,能够在浏览器或移动端界面上像人类那样点击、输入、滚动、选择控件等操作。
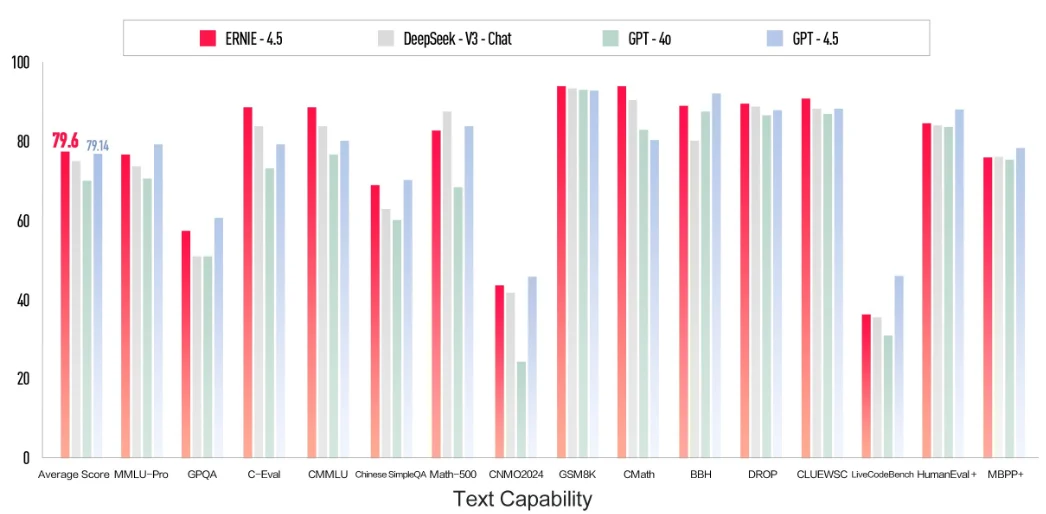
3月16日,百度宣布推出两款新一代文心大模型——ERNIE 4.5与ERNIE X1,并提前向公众免费开放其智能对话平台“文心一言”(ERNIE Bot)。官方宣称,这两款模型的能力均超过了GPT-4o,但是价格只有GPT-4o的1%,且是DeepSeek的一半。

微软发布了全新的Phi-4推理模型系列,是小型语言模型(SLM)在复杂推理能力上的一种新的尝试。本次发布包含三个不同规模和性能的推理模型,分别是Phi-4-reasoning(140亿参数)、Phi-4-reasoning-plus(增强版140亿参数)和Phi-4-Mini-Reasoning(38亿参数)。这三款模型尽管参数规模远小于当前主流大型语言模型,却在多项推理基准测试中展现出与甚至超越大型模型的能力。

GLM-4.1V-Thinking是智谱AI(Zhipu AI)与清华大学KEG实验室联合推出的多模态推理大模型。这款模型并非简单的版本迭代,而是通过一个以“推理为中心”的全新训练框架,旨在将多模态模型的能力从基础的视觉感知,推向更复杂的逻辑推理和问题解决层面。多模态理解能力接近720亿的Qwen2.5-VL-72B。
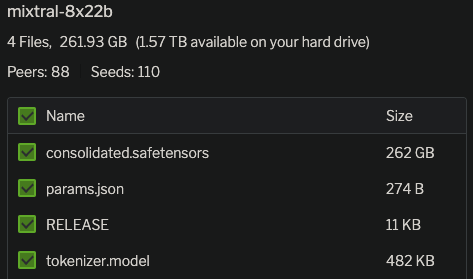
Mixtral-8×7B-MoE是由MistralAI开源的一个MoE架构大语言模型,因为它良好的开源协议和非常好的性能获得了广泛的关注。就在刚才,Mixtral-8×7B-MoE的继任者出现,MistralAI开源了全新的Mixtral-8×22B-MoE大模型。

智谱AI开源了一个60亿参数规模的文生图大模型CogView4-6B,支持生成的图像中加入文字,文字效果自然融入图像中,且该模型支持支持宽高范围512px至2048px内的任意尺寸图像(有限制,正文解释)。
Kiro 是一款AWS刚发布的、具有代理(agentic)能力的集成开发环境(IDE),它的目的是希望通过简化的开发者体验,帮助开发者从概念原型无缝过渡到生产级别的应用。它的核心理念是“规格驱动开发”(spec-driven development),以解决当前 AI 编程从有趣的原型到可靠的生产系统之间存在的鸿沟。

Scale AI 于 2025 年 9 月 21 日发布了 SWE-Bench Pro,这是一个针对 AI 代理在软件工程任务上的评估基准。该基准包含 1,865 个问题,来源于 41 个活跃维护的代码仓库,聚焦企业级复杂任务。现有模型在该基准上的表现显示出显著差距,顶级模型的通过率低于 25%,而最近的榜单更新显示部分模型已超过 40%。这一发布旨在推动 AI 在长时程软件开发中的应用研究。

智谱AI刚刚开源了新一代视觉-语言模型(Vision-Language Model, VLM)——GLM-4.5V。该模型基于其旗舰文本基础模型GLM-4.5-Air(总参数量1060亿,激活参数量120亿),延续GLM-4.1V-Thinking的技术路线,在42项公开视觉多模态基准测试中,在同规模模型中实现领先性能。GLM-4.5V面向图像、视频、文档理解以及GUI任务等常见多模态场景,采用Mixture-of-Experts(MoE)架构,并保持开源。
在大模型的应用中,处理复杂请求往往伴随着较高的延迟和成本,尤其是当请求内容存在大量重复部分时。这种“慢请求”的问题,特别是在长提示和高频交互的场景中,显得尤为突出。为了应对这一挑战,OpenAI 最近推出了 **提示缓存(Prompt Caching)** 功能。这项新技术通过缓存模型处理过的相同前缀部分,避免了重复计算,从而大幅减少了请求的响应时间和相关成本。特别是对于包含静态内容的长提示请求,提示缓存能够显著提高效率,降低运行开销。本文将详细介绍这项功能的工作原理、支持的模型,以及如何通过合理的提示结

在近年来,随着人工智能技术的飞速发展,大型语言模型(LLM)在代码生成和编辑领域的应用越来越广泛,成为软件开发中不可或缺的助手。今天,我想向大家介绍一个由BigCode项目与Software Heritage合作开发的下一代代码大型语言模型——StarCoder 2。

刚刚,X平台疑似泄露出GPT-5的评测结果,共四项评测结果,均排名第一。根据泄露的信息,GPT-5的评测包含2个不同的版本,分别是基础版本的GPT-5以及带推理模式的GPT-5 Reasoning。各项评测结果均大幅超越当前现有其它模型,都是第一!且都是断档领先!

上海人工智能实验室是国内顶尖的人工智能实验室,此前在大模型领域,他们与商汤科技发布的书生·浦语系列在国内引起了很大的关注。此次,他们又开源了一个全新的200亿参数规模的大语言模型InternLM 20B,应该是截止目前中文领域开源的参数规模最大的一个大模型了。

大模型究竟能否真正提升工程师的编码效率?Anthropic 最近发布的一份重量级内部研究给出了少见的、基于真实工程环境的数据答案。研究覆盖 132 名工程师、53 场深度访谈,以及 20 万条 Claude Code 使用记录,展示了 AI 在软件工程中的实际作用:从生产力显著提升(人均合并 PR 数同比增长 67%)、任务空间扩张(27% 的 Claude 工作原本不会被执行),到工程师技能版图、协作方式与职业路径的深刻变化。与此同时,研究也揭示了技能萎缩、监督负担、工作流变化等新挑战。这是一份罕见的“
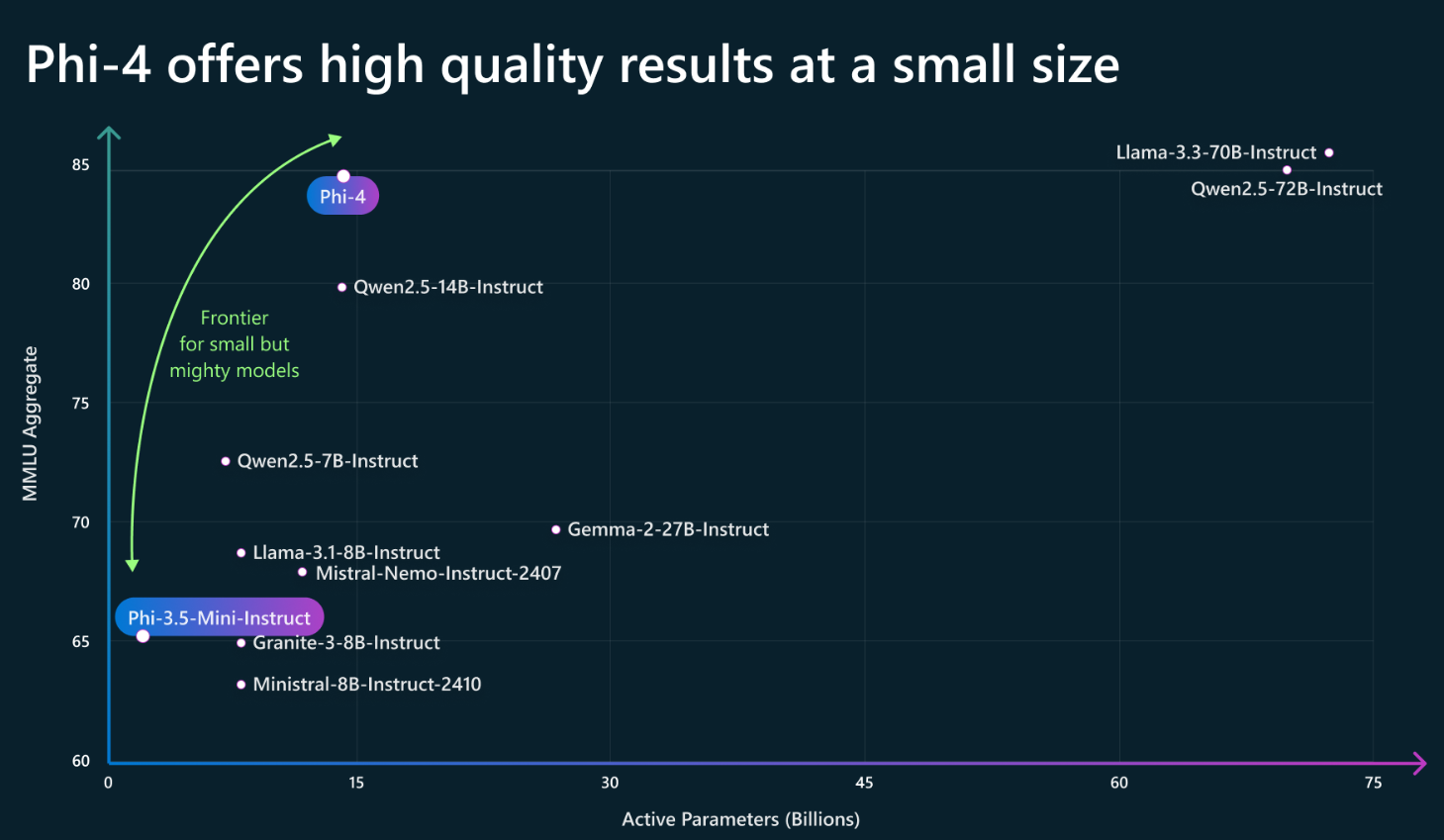
Phi大语言模型是微软发布的一系列小规模大语言模型,其主要的目标是用较小规模参数的大语言模型达成较大参数规模的大语言模型的能力。就在今天,微软发布了Phi4-14B模型,参数规模仅140亿,但是数学推理能力大幅增强,在多个评测基准上甚至接近GPT-4o的能力。
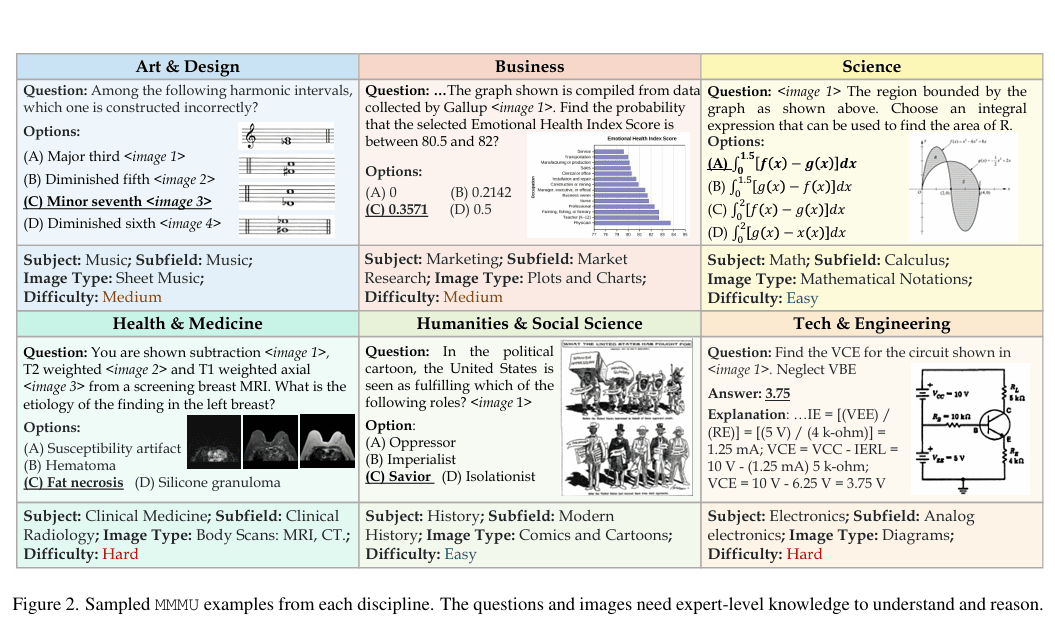
大规模多学科多模态理解与推理基准(MMMU)于2023年11月推出,是一种用于评估多模态模型的复杂工具。该基准测试人工智能系统在需要大学水平学科知识和深思熟虑推理的任务上的能力。与之前的基准不同,MMMU强调跨多个领域的先进感知和推理,旨在衡量朝专家级人工智能通用智能(AGI)的进展。

Context Arena 是一个专注于评估大语言模型长上下文处理能力的基准平台。它基于 OpenAI 发布的 Multi-Round Coreference Resolution (MRCR) 数据集,提供交互式排行榜,用于比较不同模型在复杂长对话中的信息检索和理解性能。该基准强调模型在长上下文下的实际表现,避免单纯依赖训练数据记忆。

让AI Agent通过编写代码来调用工具,而不是直接工具调用。这种方法利用了MCP(Model Context Protocol,模型上下文协议)标准,能显著降低token消耗,同时保持系统的可扩展性。下面,我结合原文的逻辑,分享我的理解和改写版本,目的是记录这个洞察,并为后续实验提供参考。Anthropic作为领先的AI研究机构,于2024年11月推出了MCP,这是一个开放标准,旨在简化AI Agent与外部工具和数据的连接,避免传统自定义集成的碎片化问题。
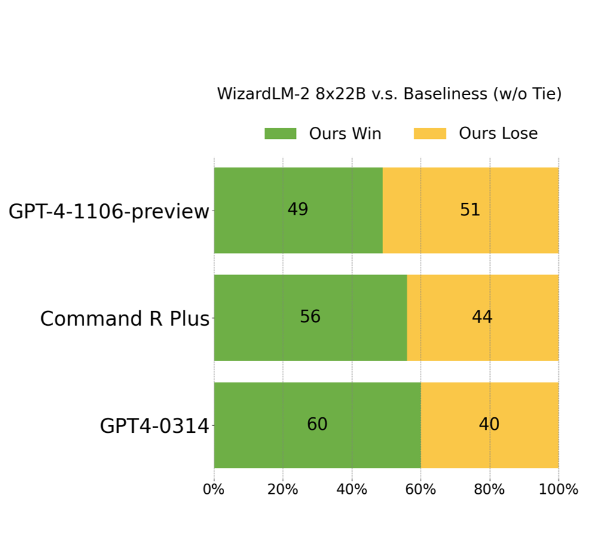
开源大模型是促进大模型技术发展最重要的技术力量之一。此次,微软以Apache 2.0开源协议开源了一个在ChatArena匿名投票评测上打败GPT-4早期版本的模型,即WizardLM-2。这是一系列模型,其中最大的版本是基于Mixtral-8×22B开源模型进行后训练得到的模型。MT-Bench得分8.96,超过了GPT-4-0314。

Assistant API是OpenAI提供的一个大模型助手类的接口,可以让开发者更加自由、准确地构建类AI Assitant系统。一个AI Assistant可以利用大模型、工具和文件来响应用户的问题。

就在刚才,Grok官网出现了Grok 4.2 Beta版本,并且已经可以直接使用。即使是免费用户,目前看也可以使用至少8次的提问。
OpenAI的o1模型被认为是大模型领域中推理能力最强的代表之一,由于其强大的数学逻辑推理能力,被认为是大模型未来的进化方向。而就在2个月之后的11月快结束的时间里,幻方量化旗下人工智能企业DeepSeekAI发布了全新的DeepSeek-R1-Lite-Preview模型,号称是o1模型的有力挑战者。该模型利用了类似的o1的思维链思索过程,推理能力大幅增强。DataLearnerAI将在本文中对该模型进行介绍,并进行几个简单的对比结果测试。结果证明这个模型是非常优秀的!

今日,Moonshot AI正式发布了最新旗舰模型 Kimi K2-Instruct-0905。这是一款基于混合专家架构(MoE)的前沿大语言模型,总参数规模达到 1万亿,激活参数为 320亿,不仅在编码智能上实现了断层式提升,更凭借 256K超长上下文 成为当前同类产品中的佼佼者。官方称其在公共基准和真实智能体任务上的表现均有显著突破,已对标并超越部分国际顶尖模型。

就在今日,阿里巴巴Qwen团队重磅推出Qwen3-VL-2B和Qwen3-VL-32B两款视觉语言模型,这些dense架构的创新之作,将多模态AI的强大能力压缩进更紧凑的框架中,显著降低了部署门槛。 作为Qwen3系列的最新扩展,它们在保持顶级性能的同时,支持从边缘设备到云端的无缝应用——想象一下,一款手机App就能实时分析2小时视频,或从模糊手写笔记中提取精确信息。这不仅仅是参数缩减,更是AI普惠化的关键一步,帮助开发者以更低的成本实现视觉智能的突破。