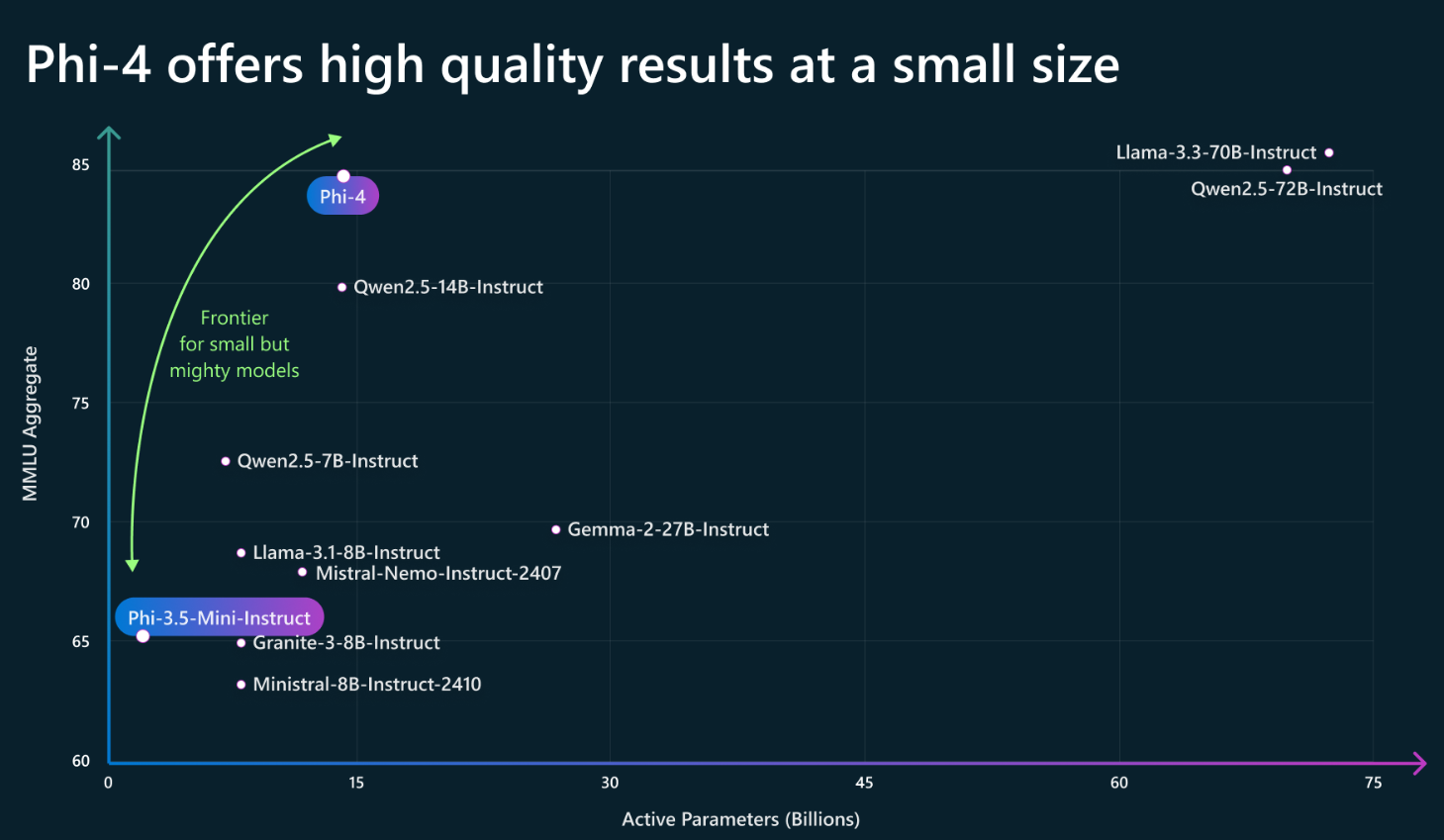
微软发布第四代Phi系列大模型,140亿参数的Phi-4 14B模型数学推理方面评测结果超过GPT 4o,复杂推理能力大幅增强
Phi大语言模型是微软发布的一系列小规模大语言模型,其主要的目标是用较小规模参数的大语言模型达成较大参数规模的大语言模型的能力。就在今天,微软发布了Phi4-14B模型,参数规模仅140亿,但是数学推理能力大幅增强,在多个评测基准上甚至接近GPT-4o的能力。
汇总「语言模型」相关的原创 AI 技术文章与大模型实践笔记,持续更新。
Phi大语言模型是微软发布的一系列小规模大语言模型,其主要的目标是用较小规模参数的大语言模型达成较大参数规模的大语言模型的能力。就在今天,微软发布了Phi4-14B模型,参数规模仅140亿,但是数学推理能力大幅增强,在多个评测基准上甚至接近GPT-4o的能力。
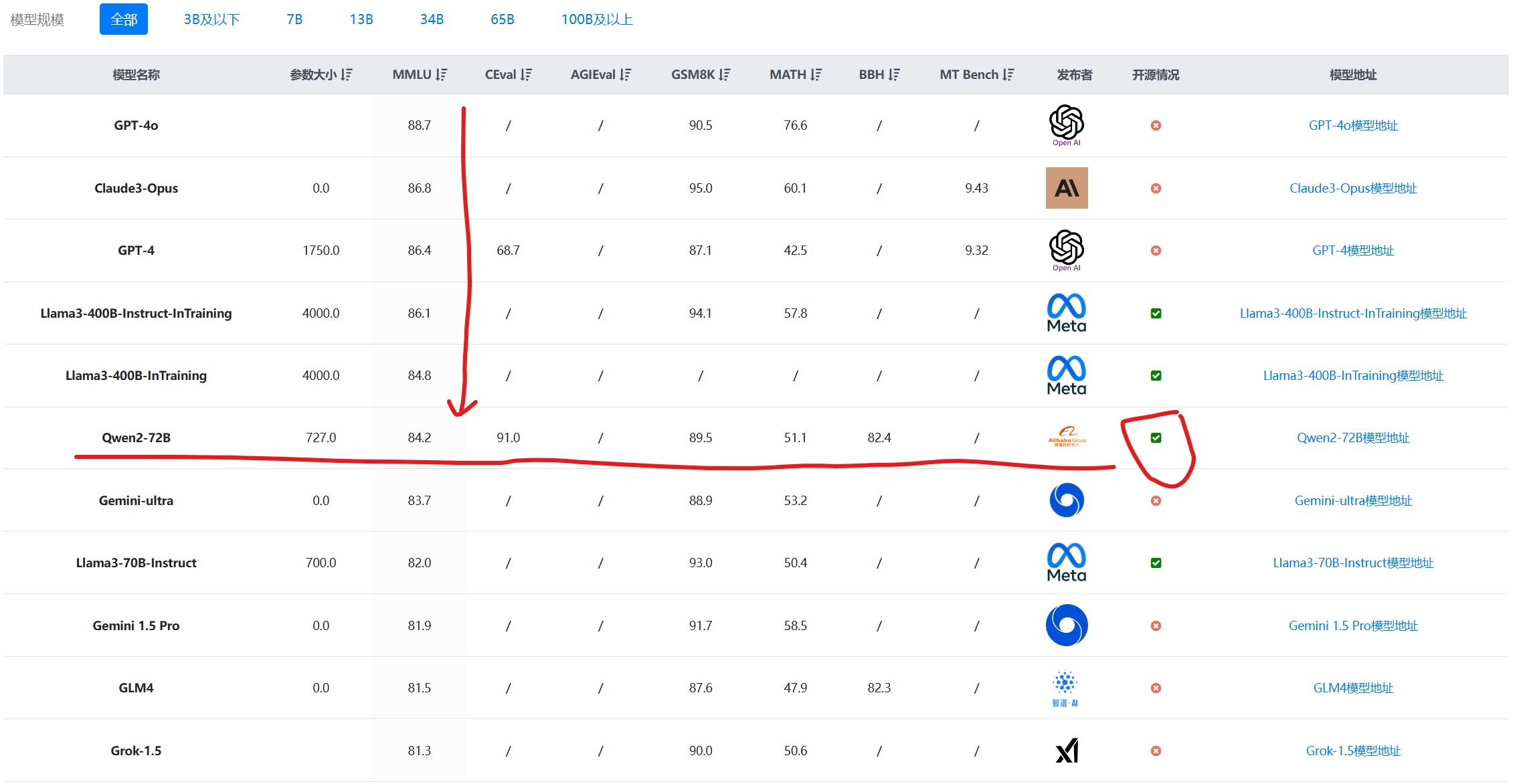
Qwen系列大语言模型是阿里巴巴开源的大语言模型。最早的Qwen模型在2023年8月份开源,当时只有70亿参数规模模型,随后阿里巴巴不断开源新的模型,最高参数规模达到了700亿,版本也从1.0升级到2024年3月份的1.5,再到今天发布的Qwen2系列。Qwen已经开源了几十个不同参数规模的大模型。此次发布的Qwen2.0系列不仅在评测任务上超过了现有的开源模型,也在实际应用中有非常好的表现。

Phi系列大语言模型是微软开源一个小规模参数的语言模型。第一代和第二代的Phi模型参数规模都不超过30亿,但是在多个评测结果上都取得了非常亮眼的成绩。今天,微软发布了第三代Phi系列大模型,最高参数规模也到了140亿,其中最小的模型参数38亿,评测结果接近GPT-3.5的水平。
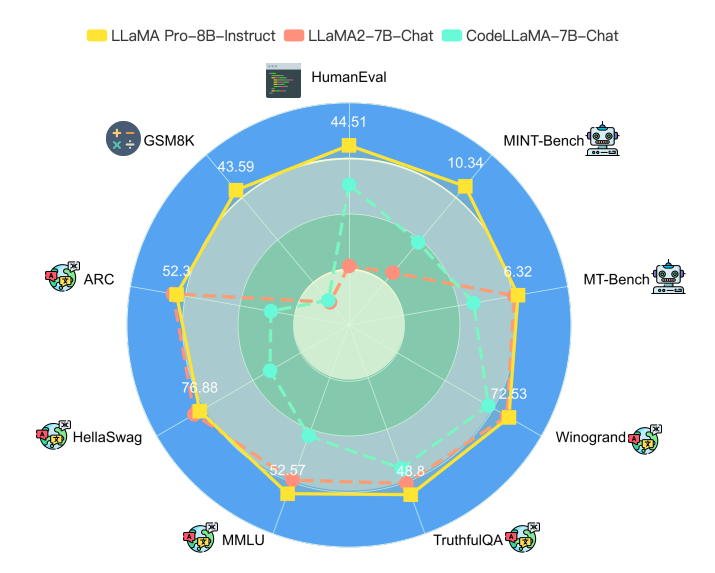
大语言模型一个非常重要的应用方式就是微调(fine-tuning)。微调通常需要改变模型的预训练结果,即对预训练结果的参数继续更新,让模型可以在特定领域的数据集或者任务上有更好的效果。但是微调一个严重的副作用是可能会让大模型遗忘此前预训练获得的知识。为此,香港大学研究人员推出了一种新的微调方法,可以保证模型原有能力的基础上提升特定领域任务的水平,并据此开源了一个新的模型LLaMA Pro。

在大语言模型中,上下文长度是指模型可以考虑的输入数据的数量。更长的上下文在大语言模型的实际应用中有非常重要的价值。当前,让大语言模型支持更长的上下文有两种常用的方法,一种是训练支持更长上下文长度的模型,扩展模型的输入,另外一种是检索增强生成的方法(Retrieval Augmentation Generation,RAG)。但二者应该如何选择,这是一个很少能直接比较的问题。为此,英伟达(Nvidia)的研究人员做了一个详细的比较。

大模型的长输入在很多场景下都有非常重要的应用,如代码生成、故事续写、文本摘要等场景,支撑更长的输入通常意味着更好的结果。昨天,斯坦福大学、加州伯克利大学和Samaya AI的研究人员联合发布的一个论文中有一个非常有意思的发现:当相关信息出现在输入上下文的开始或结束时,大模型的性能通常最高,而当大模型必须访问长上下文中间的相关信息时,性能显著下降。本文将简单介绍一下这个现象。
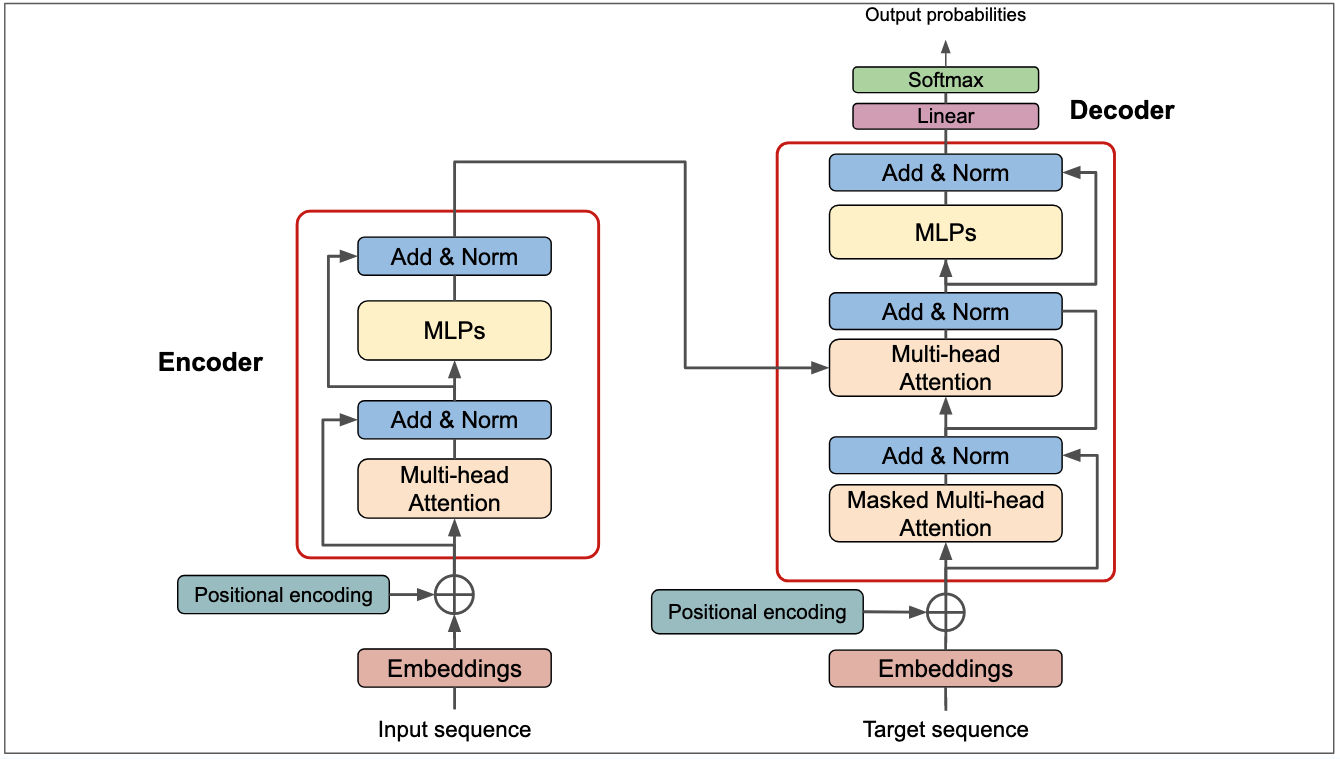
CMU的工程人工智能硕士学位的研究生Jean de Nyandwi近期发表了一篇博客,详细介绍了当前大语言模型主流架构Transformer的历史发展和当前现状。这篇博客非常长,超过了1万字,20多个图,涵盖了Transformer之前的架构和发展。此外,这篇长篇介绍里面的公式内容并不多,所以对于害怕数学的童鞋来说也是十分不错。本文是其翻译版本,欢迎大家仔细学习。
Salesforce是全球最大的CRM企业,但是在开源大模型领域,它也是一个不可忽视的力量。今天,Salesforce宣布开源全新的XGen-7B模型,是一个同时在文本理解和代码补全任务上都表现很好的模型,在MMLU任务和代码生成任务上都表现十分优秀。最重要的是,它的2个基座模型XGen-7B-4K-Base和XGen-7B-8K-Base都是完全开源可商用的大模型。
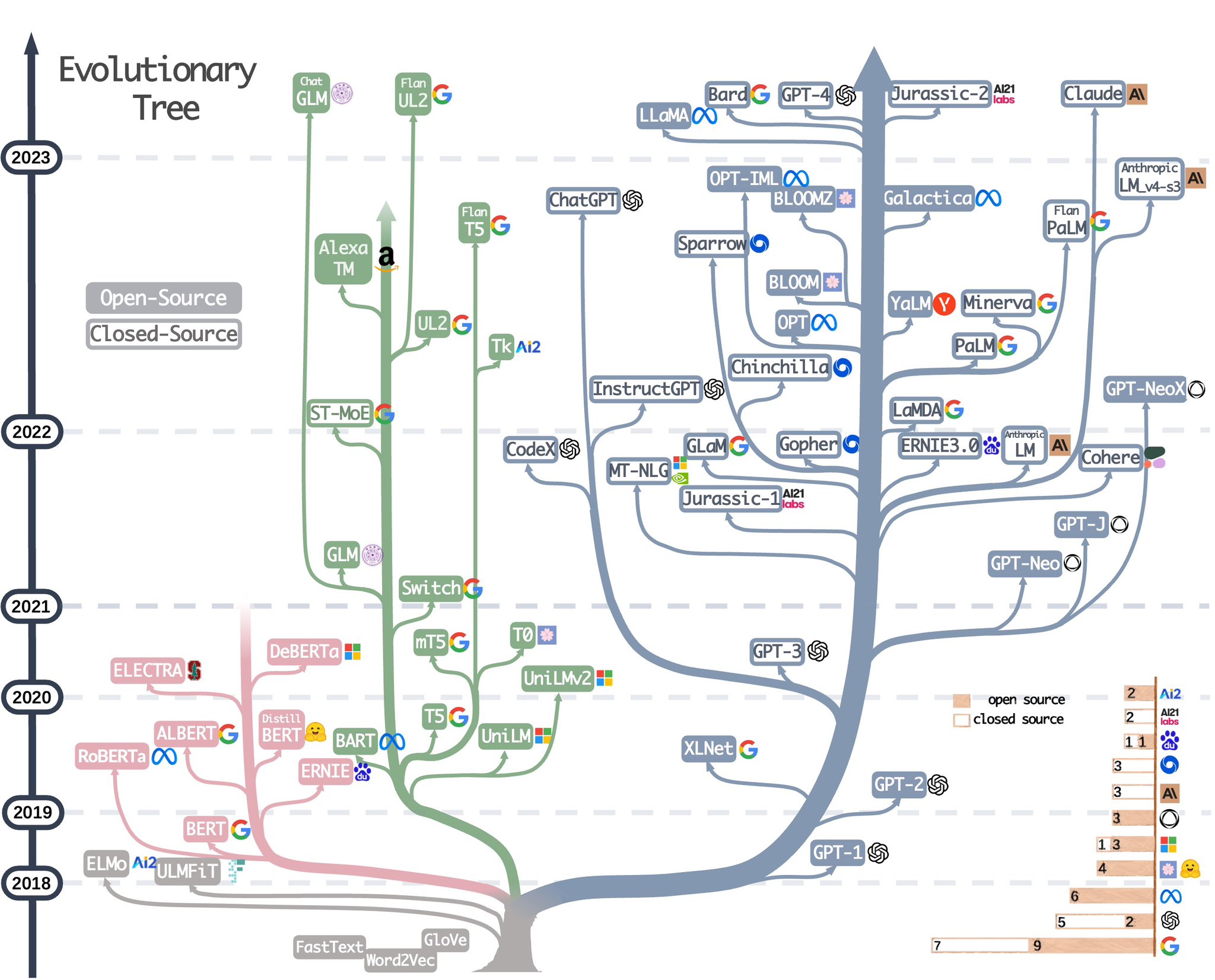
4月26日,亚马逊联合其它高校科研人员发表了一篇关于如何使用ChatGPT完成下游论文。里面使用了一个非常直观明了的大语言模型进化图总结了目前当前大语言模型的技术架构分类和开源现状,十分受欢迎。因此,4月30日,作者再次更新这幅图,增加了更多的大语言模型。
5月27日,OpenBMB发布了一个最高有100亿参数规模的开源大语言模型CPM-BEE,OpenBMB是清华大学NLP实验室联合智源研究院成立的一个开源组织。该模型针对高质量中文数据集做了训练优化,支持中英文。根据官方的测试结果,其英文测试水平约等于LLaMA-13B,中文评测结果优秀。
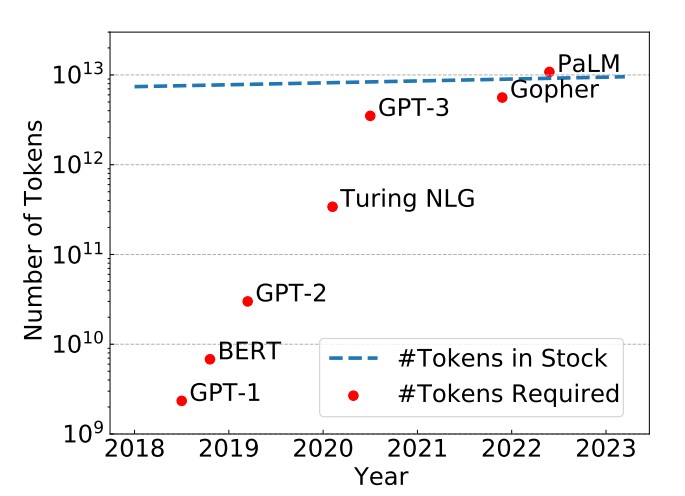
epoch是一个重要的深度学习概念,它指的是模型训练过程中完成的一次全体训练样本的全部训练迭代。然而,在LLM时代,很多模型的epoch只有1次或者几次。这似乎与我们之前理解的模型训练充分有不一致。那么,为什么这些大语言模型的epoch次数都很少。如果我们自己训练大语言模型,那么epoch次数设置为1是否足够,我们是否需要更多的训练?

昨天,HuggingFace的大语言模型排行榜上突然出现了一个评分超过LLaMA-65B的大语言模型:Falcon-40B,引起了广泛的关注。本文将简要的介绍一下这个模型。截止2023年5月27日,Falcon-40B模型(400亿参数)在推理、理解等4项Open LLM Leaderloard任务上评价得分第一,超过了之前最强大的LLaMA-65B模型。
今天,推特上一位科技博主SullyOmarr分享了一个关于embedding的内容十分火爆。主要介绍为什么embedding对于在目前的AI大模型中很重要。这是一个十分不错的关于embedding知识的介绍。本文将根据SullyOmarr的内容也对embedding做一个简单的介绍,并解释为什么它在大语言模型中十分重要。
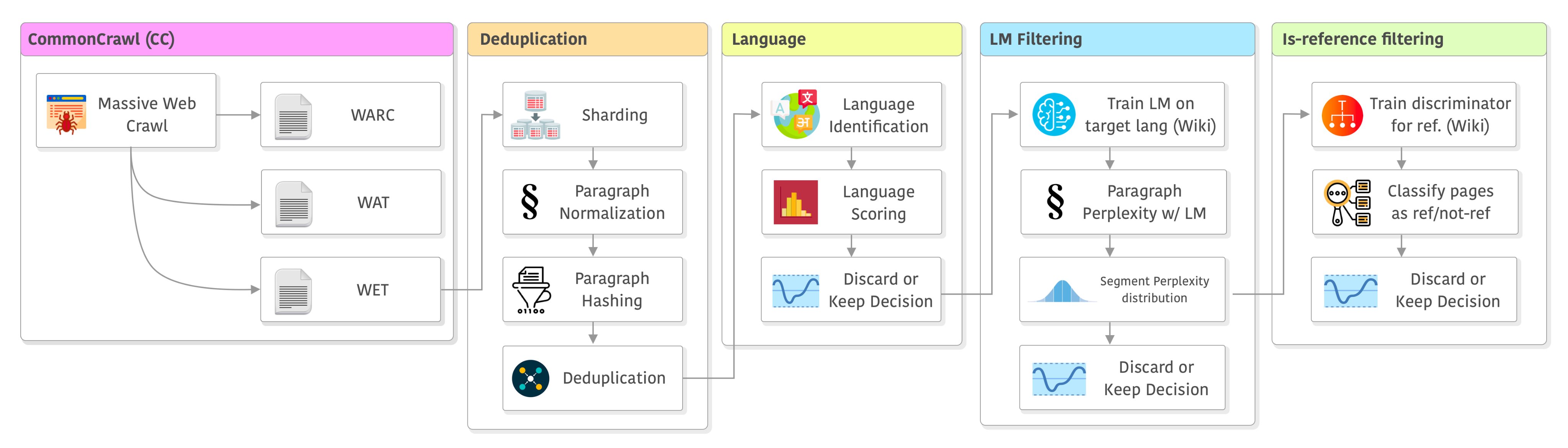
大语言模型的训练是一个十分复杂的技术,不仅涉及到模型的开发与部署,还涉及到数据的获取。与常规的算法模型不同的是,大语言模型通常需要大量的数据处理步骤。本文是根据英国一位自动工程师总结的大语言模型训练之前的数据处理步骤和决策过程。
尽管当前ChatGPT和GPT-4非常火热,但是高昂的训练成本和部署成本其实导致大部分个人、学术工作者以及中小企业难以去开发自己的模型。使得使用OpenAI的官方服务几乎成为了一种无可替代的选择。本文介绍的是一种低成本开发高效ChatGPT的思路,我认为它适合一些科研机构去做,也适合中小企业创新的方式。这里提到的思路涉及了一些最近发表的成果和业界的一些实践产出,大家可以参考!

最近,随着ChatGPT的火爆,大语言模型(Large language model)再次被大家所关注。当年BERT横空出世的时候,基于BERT做微调风靡全球。但是,最新的大语言模型如ChatGPT都使用强化学习来做微调,而不是用之前大家所知道的有监督的学习。这是为什么呢?著名AI研究员Sebastian Raschka解释了这样一个很重要的转变。大约有5个原因促使了这一转变。

今天,时隔一年后,OpenAI发布了第二代的DALL·E模型。相比较第一代的模型,DALL·E 2,以4倍的分辨率生成更真实和准确的图像。
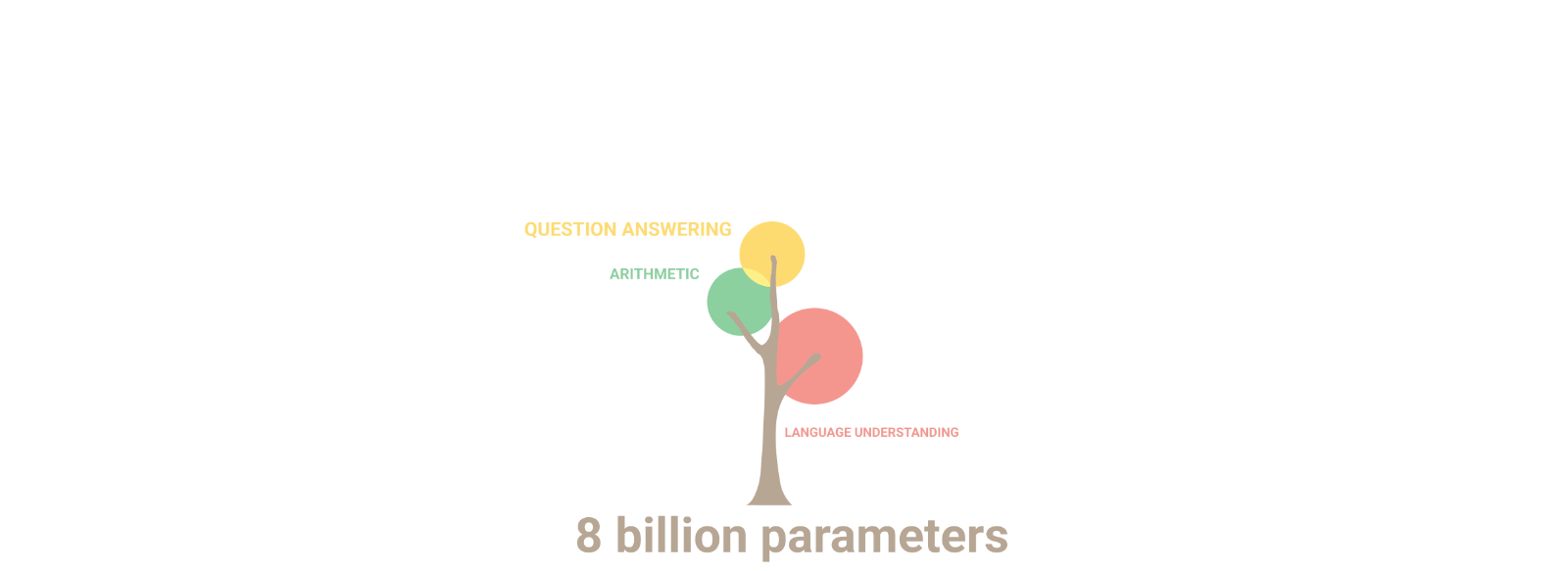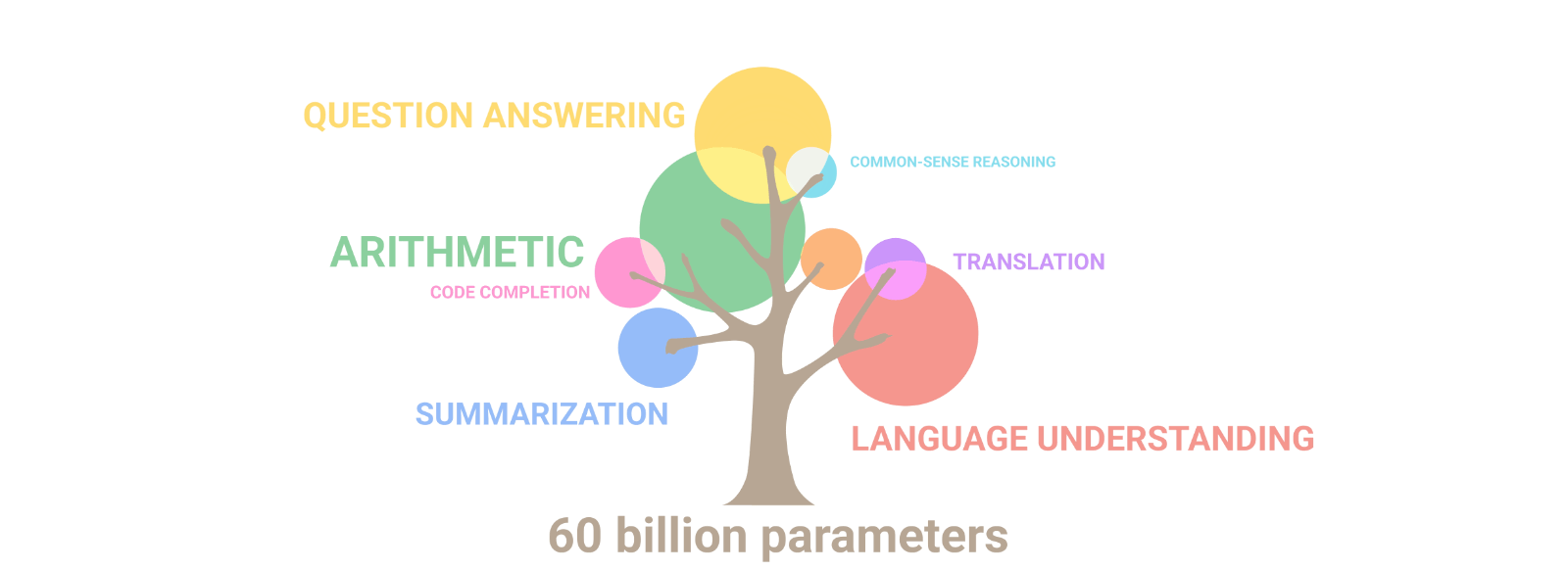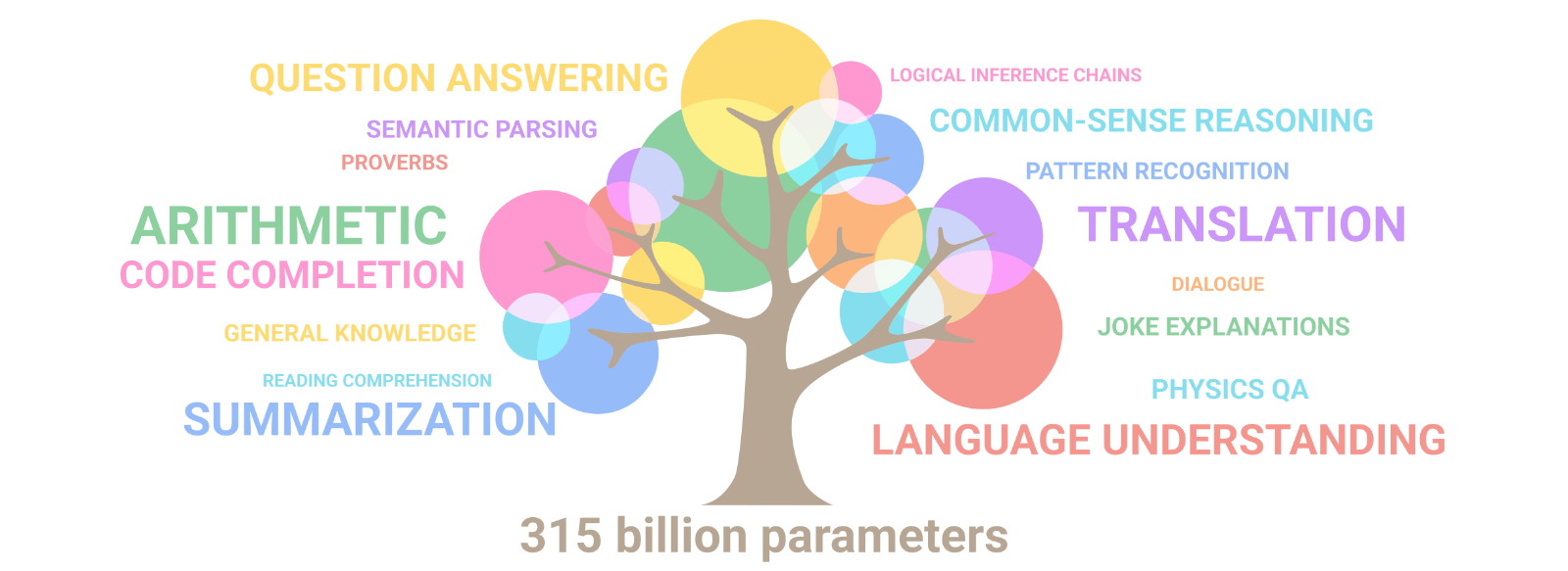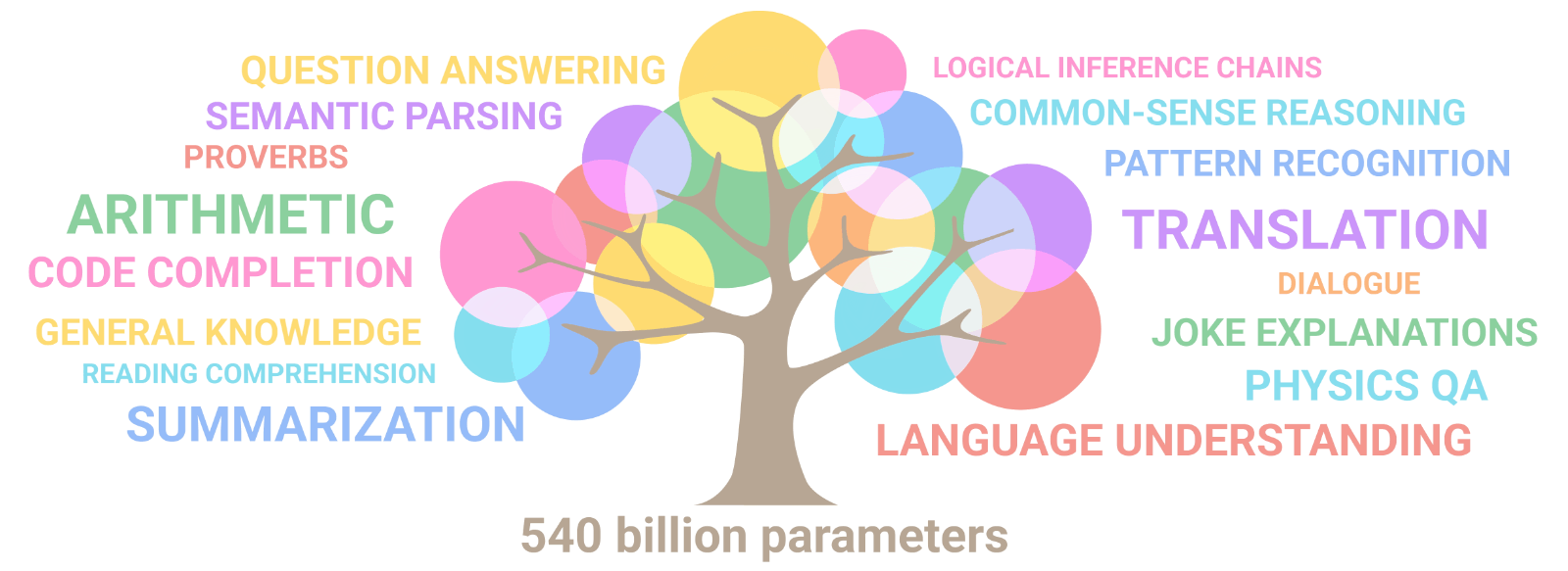
今天,Google介绍了一个新的语言模型,一个Pathways语言模型:PaLM,这是一个用Pathways系统训练的5400亿个参数、仅有dense decoder的Transformer模型,在数百个语言理解和生成任务上对PaLM进行了评估,发现它在大多数任务中实现了最先进的性能,在许多情况下都有显著的优势。
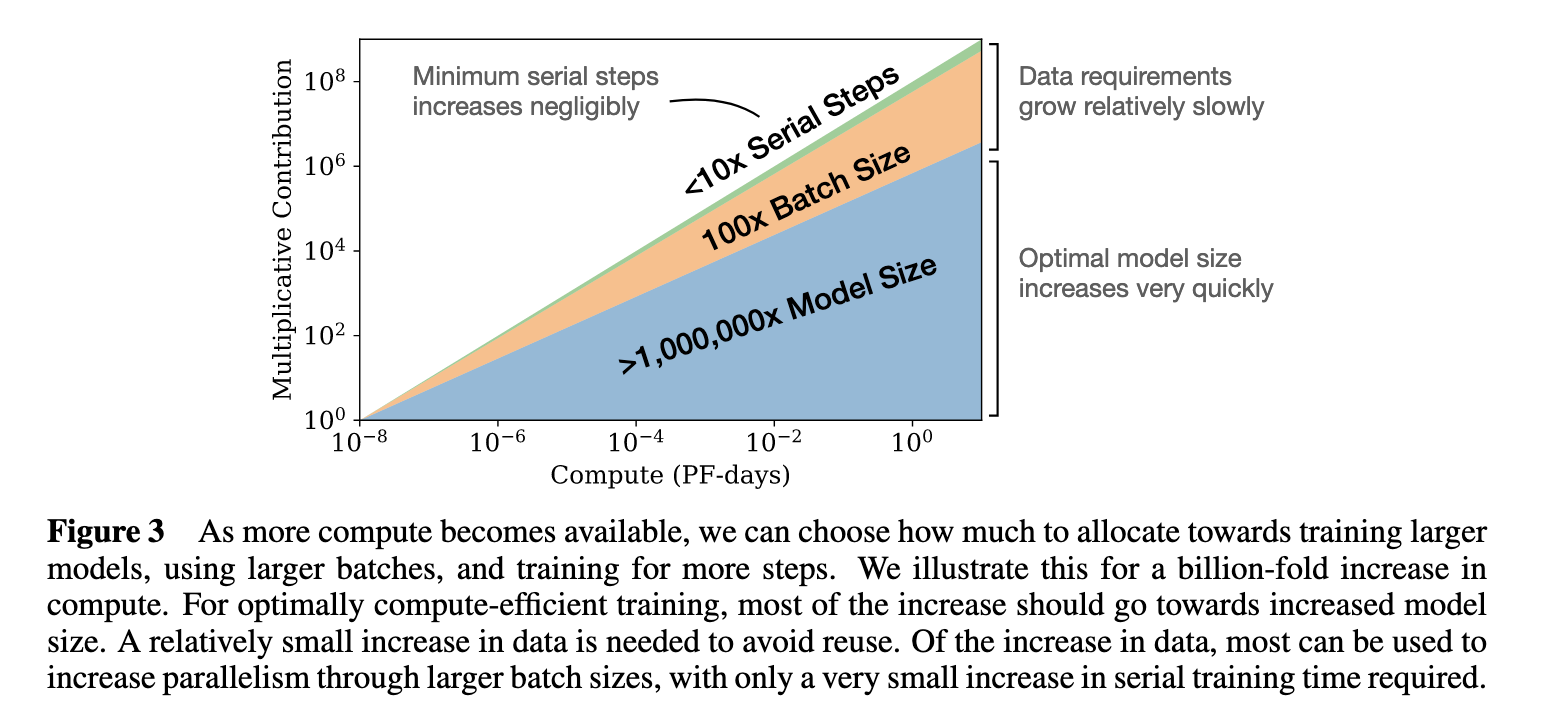
3月29日,DeepMind发表了一篇论文,"Training Compute-Optimal Large Language Models",表明基本上每个人--OpenAI、DeepMind、微软等--都在用极不理想的计算方式训练大型语言模型。论文认为这些模型对计算的使用一直处于非常不理想的状态。并提出了新的模型缩放规律。