
最近很火的基于人工智能(AI)的vibe coding是什么?它和传统软件编码之间有什么区别?
“Vibe Coding”(氛围编程)是一种新兴的编程范式,强调通过自然语言与人工智能(AI)协作开发软件。该概念由前 OpenAI 研究员 Andrej Karpathy 于 2025 年提出,旨在让开发者沉浸于创作氛围中,利用 AI 的能力,将自然语言描述转化为实际源代码,从而简化编程过程。
探索人工智能与大模型最新资讯与技术博客,涵盖机器学习、深度学习、自然语言处理等领域的原创技术文章与实践案例。
“Vibe Coding”(氛围编程)是一种新兴的编程范式,强调通过自然语言与人工智能(AI)协作开发软件。该概念由前 OpenAI 研究员 Andrej Karpathy 于 2025 年提出,旨在让开发者沉浸于创作氛围中,利用 AI 的能力,将自然语言描述转化为实际源代码,从而简化编程过程。

随着大语言模型(LLM)的发展越来越快,我们需要更好的方法来评估它们到底有多“聪明”,特别是在处理复杂数学问题的时候。AIME 2025 就是这样一个工具,它专门用来测试当前 AI 在高等数学推理方面的真实水平。

阿里巴巴Qwen团队发布了全新的Qwen3 Embedding系列模型,这是一套基于Qwen3基础模型构建的专用文本向量与重排(Reranking)模型。该系列模型凭借Qwen3强大的多语言理解能力,在多项文本向量与重排任务的Benchmark上达到了SOTA水平,其中8B尺寸的向量模型在MTEB多语言排行榜上排名第一。Qwen3 Reranker模型在多个评测基准上同样大幅超越了现有的主流开源竞品。

OpenAI 正式发布了其最新模型 OpenAI o3-pro,这是其旗舰模型 o3 的专业增强版。o3-pro 专为需要“更长时间思考”的复杂任务而设计,其核心亮点在于极致的可靠性和准确性,尤其在数学、科学和编程等专业领域表现卓越。根据OpenAI引入的全新“4/4可靠性”评测标准,o3-pro 的性能远超前代,OpenAI官方强调o3-pro在处理高难度、高风险任务的能力上实现了质的飞跃。

Mistral AI今天发布了其首个专注于推理能力的系列模型——**Magistral**。这次发布包含两个核心模型:旗舰模型`Magistral Medium`和<font color=red>已开源的</font>`Magistral Small (24B)`。最引人注目的亮点是,Mistral展示了其自研的强化学习(RL)pipeline能够从头开始,仅通过RL训练就将基础模型的推理能力提升到业界顶尖水平,而无需依赖任何其他预先存在的推理模型进行数据蒸馏。这套技术栈非常强大!


MiniMaxAI于2025年6月17日正式发布了其新一代大模型——MiniMax-M1。MiniMax-M1的核心亮点在于结合了混合专家(MoE)架构和创新的闪电注意力(Lightning Attention)机制。MiniMax-M1不仅原生支持高达100万Token的上下文长度,推理的tokens也支持最高80K,是当前支持的最多推理长度的大模型。此外,MiniMax-M1在计算效率上也很高,例如在生成10万Token时,其FLOPs消耗仅为DeepSeek R1的25%!

今天,Google发布Gemini 2.5 Flash Lite。这是一款专为追求极致速度、超低延迟和高性价比场景打造的轻量级模型。它的发布标志着 Google 正在将旗舰模型的先进能力(如百万级上下文、原生多模态、工具调用等)逐步下放到更轻量、更经济的模型层级。根据 DataLearnerAI 的实测,这款模型的生成速度最高可达 400 tokens/秒,即使在输入达到 18K tokens 的情况下,也依然可以维持在 160+ tokens/秒 的性能表现,令人惊喜。

Qwen3 是阿里于 2025 年 6 月开源的新一代大模型系列,共发布了 8 个不同参数规模的模型,覆盖从 6 亿到 2350 亿参数的范围,融合了稠密模型和 MoE 架构。值得注意的是,此次未包含此前广受关注的 Qwen-72B 稠密模型版本,阿里表示从 Qwen3 起,超过 30B 参数的模型将统一采用 MoE 架构以优化性能和效率。

今天,Google为全球开发者社区带来了一款激动人心的新工具——**Gemini CLI**。这是一款免费、开源的AI智能体,它将Google当前最强大的模型Gemini 2.5 Pro的能力,直接集成到了开发者最熟悉的命令行界面(CLI)中。对于那些视终端为“家”的开发者来说,这无疑是一个重大的升级。它不仅擅长编码,更是一个可以处理内容生成、问题解决、深度研究和任务管理的多功能本地实用工具。它的发布,旨在为个人开发者提供前所未有的便捷AI体验,非常强大!

继Gemma系列模型发布并迅速形成超过1.6亿次下载的繁荣生态后,Google再次推出了其在端侧AI领域的重磅力作——Gemma 3n。这款模型并非一次简单的迭代,而是基于全新的移动优先(mobile-first)架构,旨在为开发者提供前所未有的设备端多模态处理能力。Gemma 3n的定位是成为一款高效、强大且灵活的开源模型,直接与设备端AI领域的其他先进模型(如Phi-4、Llama系列的小参数版本)竞争,其核心特性在于原生支持图像、音频、视频和文本输入。

腾讯发布并开源了其混元大模型系列的新成员Hunyuan-A13B。该模型定位为一个基于细粒度专家混合(MoE)架构的大语言模型。其主要特点是高效率和可扩展性,旨在为开发者和研究人员,特别是在资源受限的环境中,提供高级推理和通用应用能力。Hunyuan-A13B是由原来的微软的WizardLM团队成员打造,评测结果超Qwen2.5-72B和Qwen3-A22B

昨天,Anthropic公布了一项引人注目的实验——Project Vend。他们让旗下的大模型Claude Sonnet 3.7在一个真实的办公环境中,自主经营一家小型自动化商店,为期约一个月。这个实验的目标是探索,在不久的将来,AI模型在真实经济体中自主运行任务的可行性、潜在的成功模式以及那些出人意料的失败方式。实验结果非常强大,也充满了令人深思的细节!
2025年6月26日,阿里达摩院正式发布了全新的Qwen VLo大模型。这是继QwenVL和Qwen2.5 VL后,阿里在多模态大模型领域又一具有里程碑意义的创新。Qwen VLo是一款统一的多模态理解与生成模型,不仅具备深度理解图片与文本内容的能力,更能基于这种理解实现高质量和高度一致的图像生成与编辑,真正跨越了“感知”与“创造”的界限。

今天,百度正式宣布开源其最新的旗舰级大模型系列——ERNIE 4.5。ERNIE 4.5系列模型当前包含2个多模态大模型,4个大语言模型及其不同变体的庞大家族,还区分了PyTorch版本和paddlepaddle版本,共23个模型,其核心采用了创新的异构多模态混合专家(MoE)架构,在提升多模态理解能力的同时,实现了文本处理性能的同步增强。每个版本的模型都开源了基座(Base)版本和后训练版本(不带Base)。

盘古大模型是华为自研的大语言模型,基于华为的硬件和技术栈进行训练。此前一直被认为是国产技术占比很高的国产大模型。今天,华为开源了2个盘古大模型,分别是MoE架构的Pangu Pro MoE模型以及70亿参数规模的Pangu Embedded模型。
Ai2近日发布的全新评测平台——SciArena,为这一痛点带来了创新解法。此次产品不仅继承了“人类众包对比评测”的理念,更结合科学问题的独特复杂性,构建了开放、透明且可迭代的模型评测生态。

GLM-4.1V-Thinking是智谱AI(Zhipu AI)与清华大学KEG实验室联合推出的多模态推理大模型。这款模型并非简单的版本迭代,而是通过一个以“推理为中心”的全新训练框架,旨在将多模态模型的能力从基础的视觉感知,推向更复杂的逻辑推理和问题解决层面。多模态理解能力接近720亿的Qwen2.5-VL-72B。
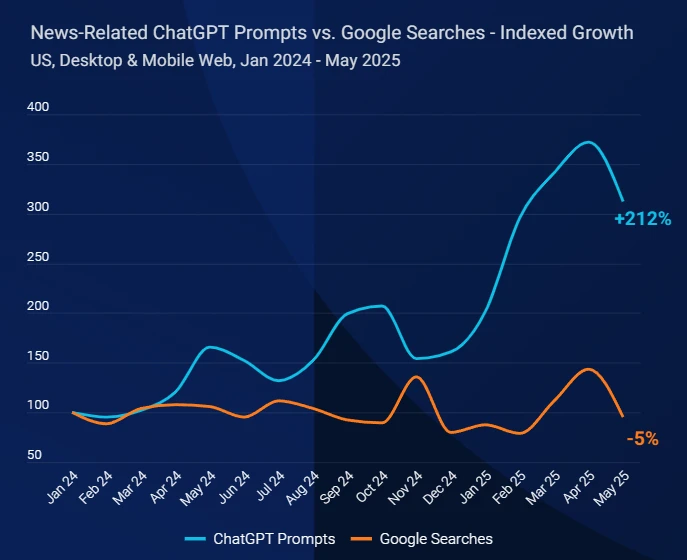
今天,SimilarWeb发布了一个全新的报告,描述了自从ChatGPT这种大模型产品发布之后,新闻出版网站的流量下滑严重,并提供了相关的分析。尽管这是针对新闻网站的报告,但是实际上所有的内容网站或者是内容生产者可能都是有影响的。我们基于这份报告进行解读,为大家提供一个参考。

Grok4是马斯克旗下大模型初创企业xAI的第四代代码,在五月份的时候,马斯克就透露他们马上要发布Grok 3.5模型,六月份的时候说这个模型效果很好,版本号就直接改为4,这中间经过多次波折,最终马斯克说Grok 4将在7月4日之后发布。截止目前,虽然xAI官方没有正式宣布Grok 4,但是目前Grok 4已经透露了很多的消息。本文将对这些信息做总结和分析。
Manus AI 是一款尖端的人工智能代理程序,于 2025 年 3 月 6 日正式发布,旨在跨多个领域自主执行复杂任务,弥合人类意图与可操作结果之间的差距。它由 Butterfly Effect 开发,该公司在中国(北京和武汉)以及新加坡(BUTTERFLY EFFECT PTE. LTD.)设有运营机构。以下内容基于截至 2025 年 7 月 5 日的最新信息,涵盖其产品功能、关键技术特点及用户反馈。
人工智能(AI)的通用智能(AGI)发展一直是研究领域的焦点。近期,由 ARC Prize 基金会推出并由 AI 研究者 François Chollet 联合发起的 ARC-AGI-2 评测基准,为衡量大模型在未知情境下的实时推理能力和学习效率提供了新的视角。

马斯克旗下的xAI公司正式发布Grok4大模型,包含Grok 4和Grok4 Heavy版本,其中Grok4 Heavy是一个Agent系统,在AIME2025(美国的数学邀请赛)得分满分,超过了所有大模型。此前透露的Grok 4 Code和视频生成能力都没有发布。

编程领域大模型一直是进展非常快的大模型领域。因为编程能力更强的模型,通常在逻辑思维、工具调用上有更好的表现,在很多领域,特别是Agent领域有很大的应用价值。今天法国人工智能明星公司MistralAI发布了2个全新的编程大模型,分别是Devstral Medium和 Devstral Small 1.1,后者是一个开源的240亿参数的编程大模型。