Moonshot AI 发布 Kimi K2 Thinking:连续执行200-300次顺序工具调用,人类最后难题评测得分超过所有模型,全球第一!依然免费开源商用!
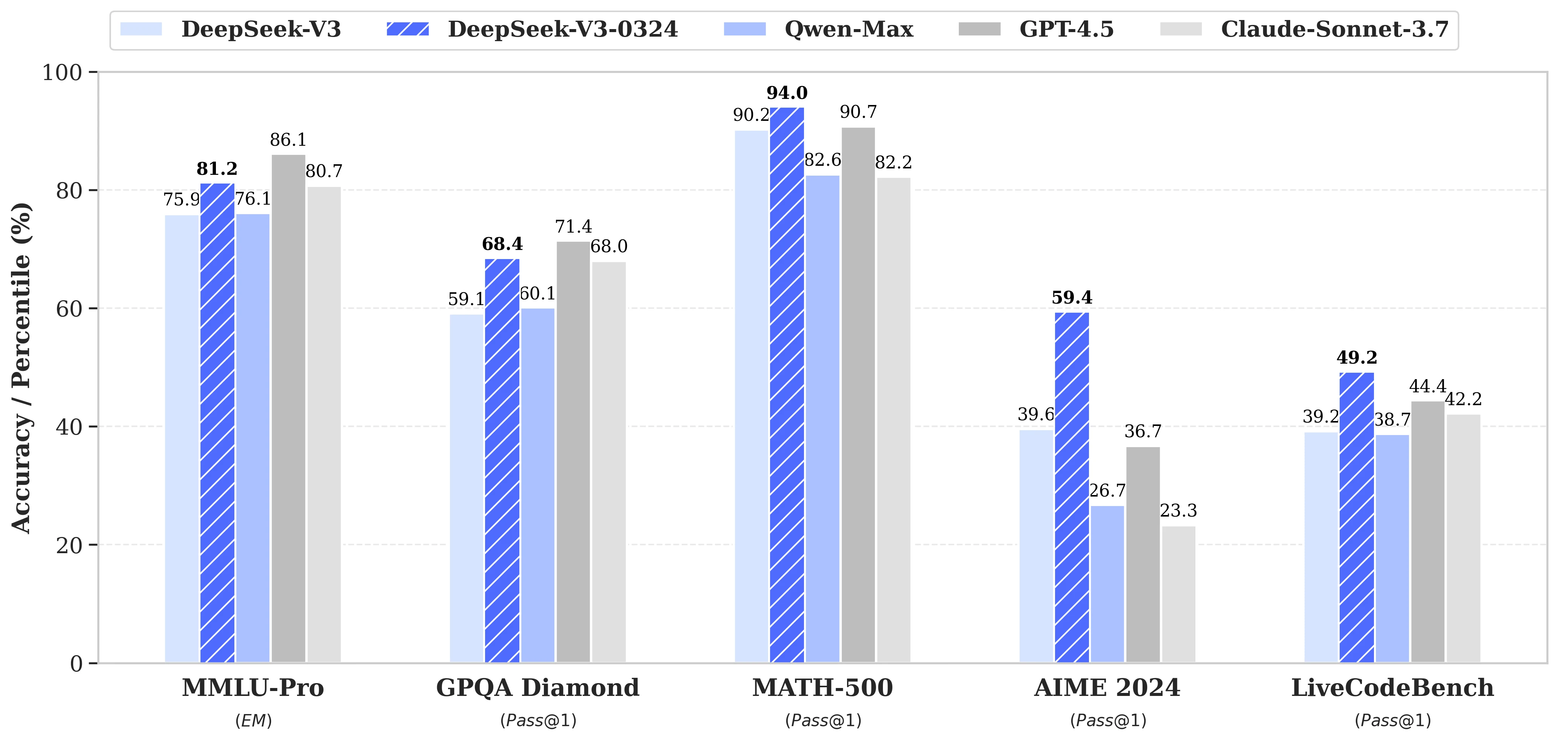
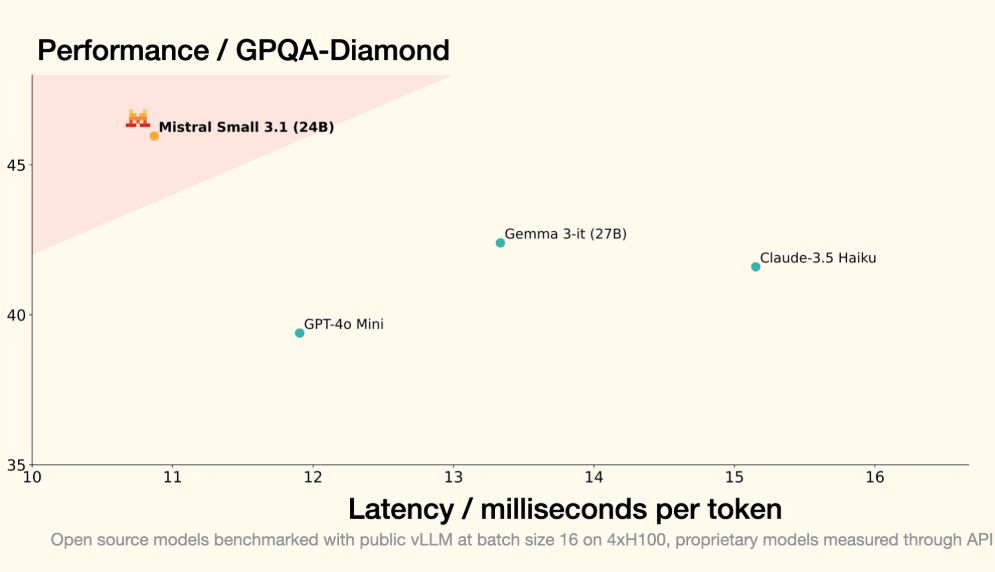
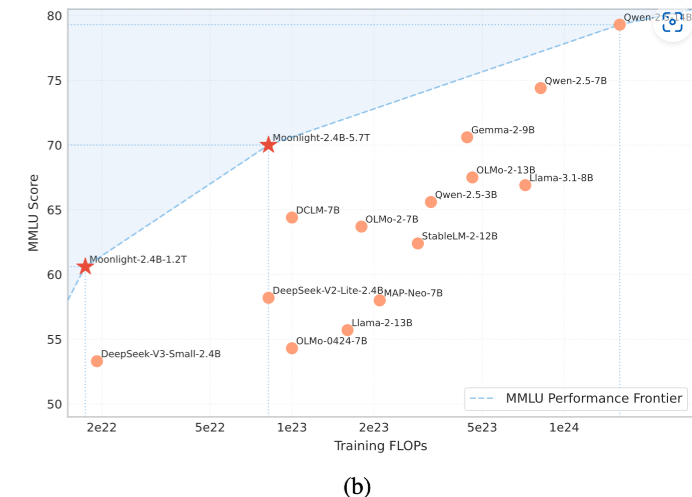
就在今日,Moonshot AI 正式推出 Kimi K2 Thinking,这款开源思考代理模型以其革命性的工具集成和长程推理能力,瞬间点燃了开发者社区的热情。Kimi K2能自主执行200-300次连续工具调用,跨越数百步推理,解决PhD级数学难题或实时网络谜题。本次发布的Kimi K2不仅仅是模型升级,更是AI Agent能力的扩展。