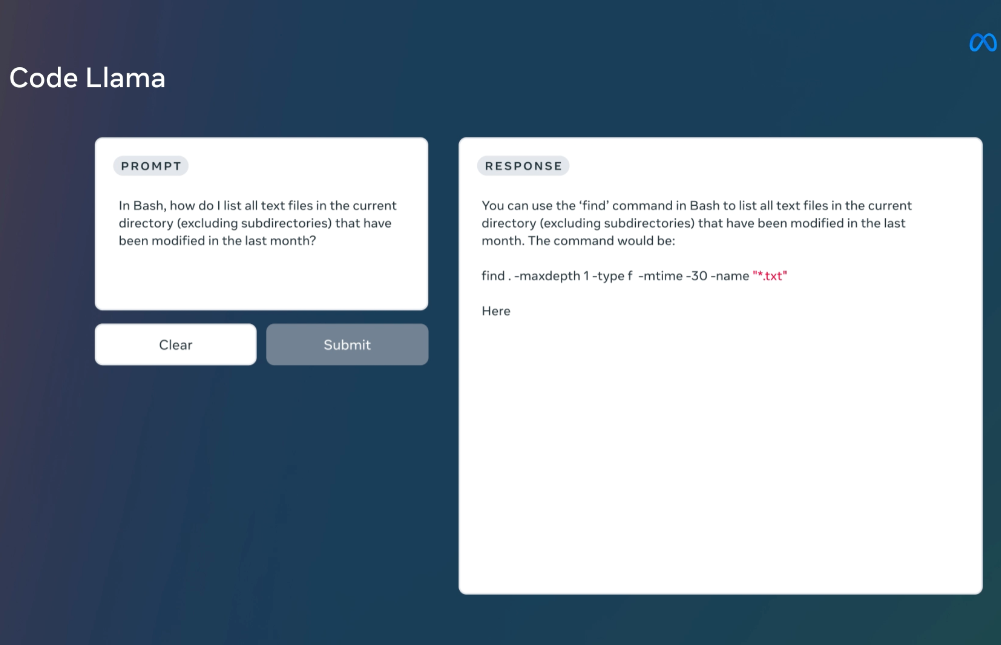
MetaAI官宣开源编程大模型CodeLLaMA!基于LLaMA2微调!超越OpenAI的Codex,最高支持10万tokens输入!
MetaAI发布的LLaMA系列开源大语言模型已经是开源大模型领域最重要的力量了。相当多的所谓开源大模型都是基于这个模型微调得到。在上个月,LLaMA2发布,吸引了全球非常多的关注,也有相当多的后续模型基于LLaMA2进行优化。而今天MetaAI再次开源全新的编程大模型——CodeLLaMA系列,这是MetaAI第一次发布编程大模型,本次发布的CodeLLaMA共有9个版本,分别是CodeLLaMA系列、针对Python优化的CodeLLaMA-Python系列和针对指令优化的CodeLLaMA-Inst