目前业界支持中文大语言模型开源和商用许可协议总结
目前,业界开源的大语言模型越来越多,性能也越来越强大。然而,这些开源模型大多数由国外的机构贡献,对于英文的支持没有任何问题。但是,对于中文的支持则是有好有坏。本文将基于主流的开源大模型进行分析,介绍当前支持中文的开源大模型,并对其使用方式和主要能力进行总结。
汇总「模型」相关的原创 AI 技术文章与大模型实践笔记,持续更新。
目前,业界开源的大语言模型越来越多,性能也越来越强大。然而,这些开源模型大多数由国外的机构贡献,对于英文的支持没有任何问题。但是,对于中文的支持则是有好有坏。本文将基于主流的开源大模型进行分析,介绍当前支持中文的开源大模型,并对其使用方式和主要能力进行总结。
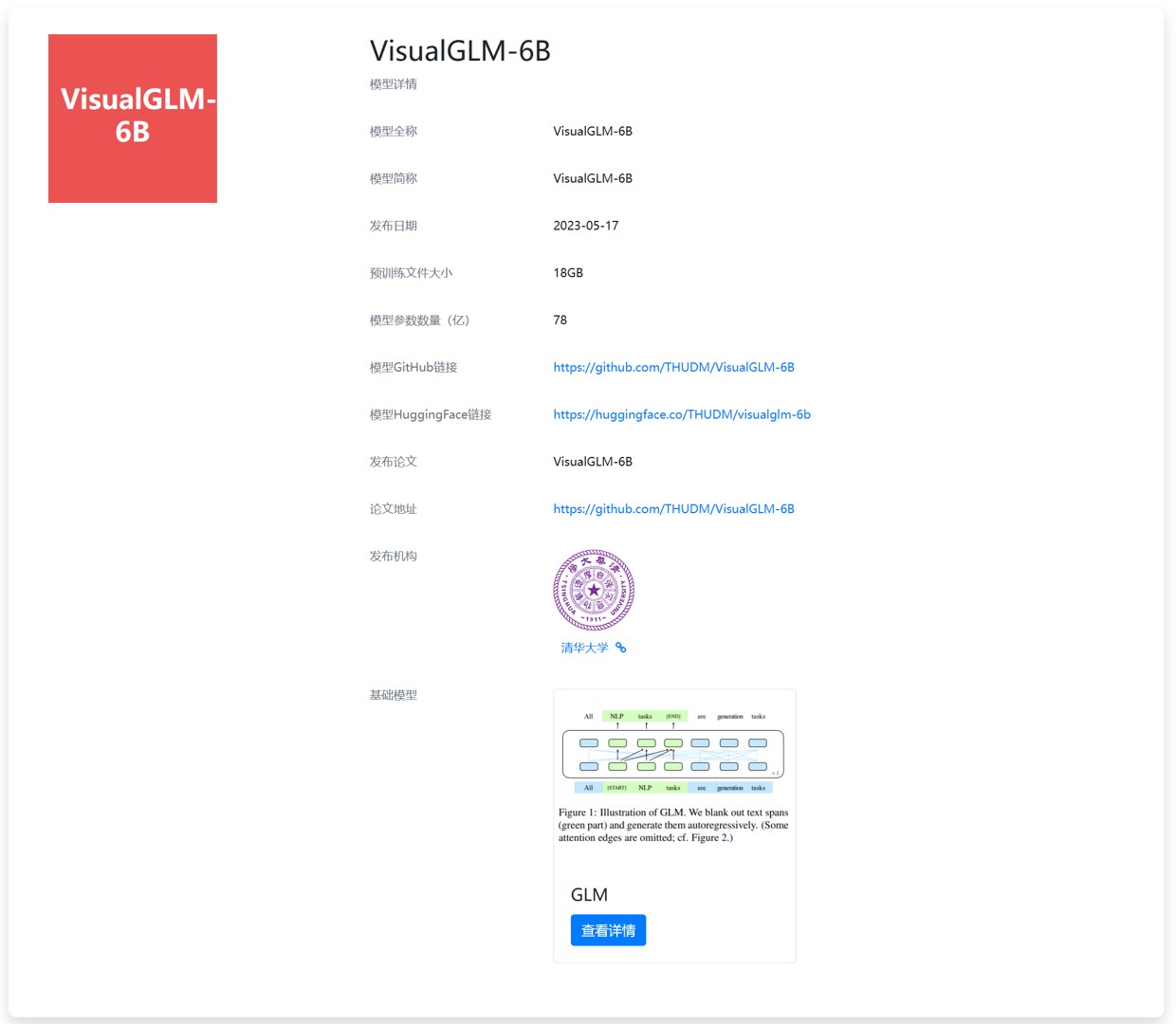
今天,THUDM开源了ChatGLM-6B的多模态升级版模型VisualGLM-6B。这是一个多模态对话语言模型,支持图像、中文和英文。VisualGLM-6B的特别之处在于它能够整合视觉和语言信息。可以用来理解图片,解析图片内容。
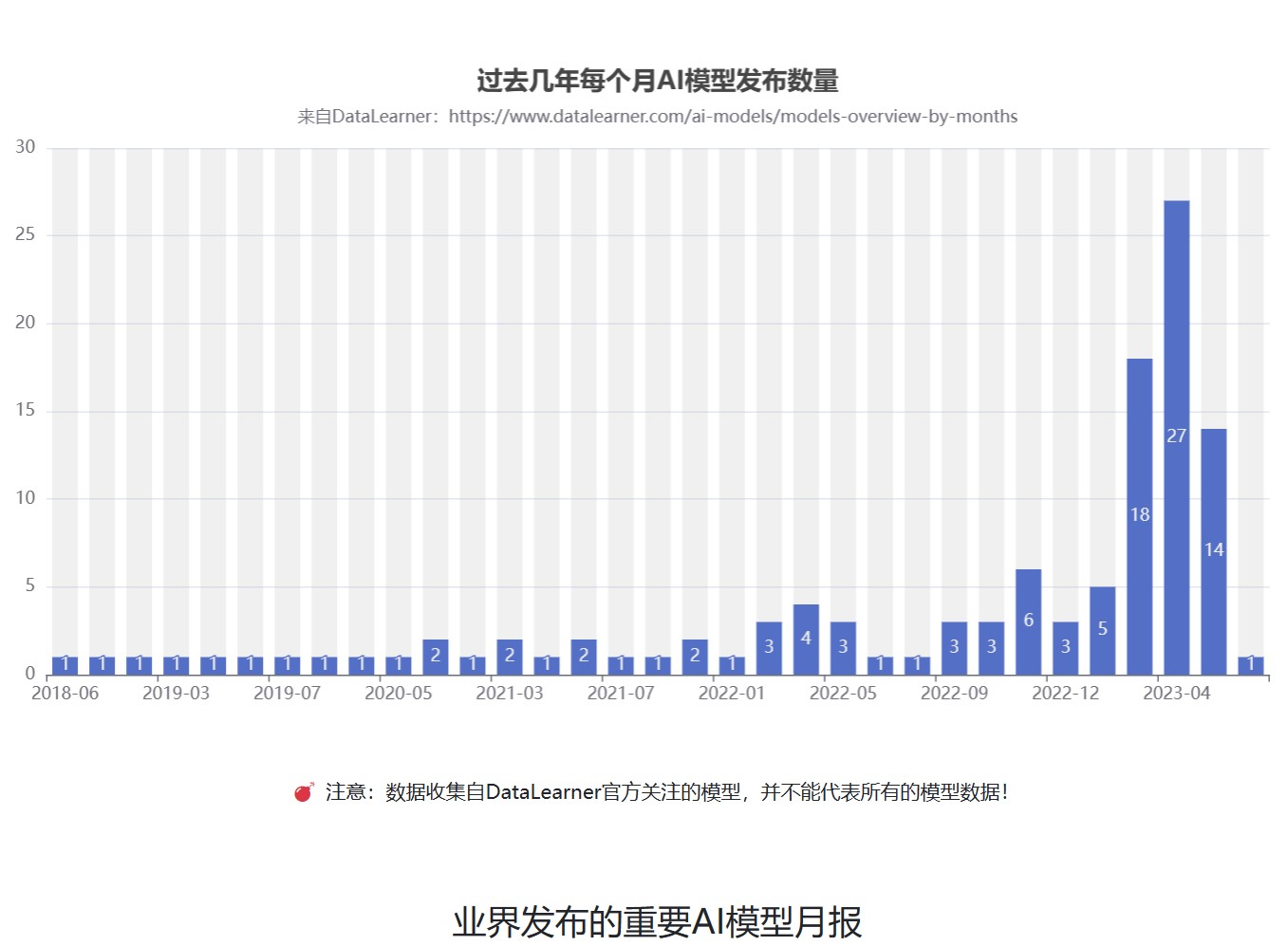
2022年11月底,OpenAI发布ChatGPT,2023年3月14日,GPT-4发布。这两个模型让全球感受到了AI的力量。而随着MetaAI开源著名的LLaMA,以及斯坦福大学提出Stanford Alpaca之后,业界开始有更多的AI模型发布。本文将对4月份发布的这些重要的模型做一个总结,并就其中部分重要的模型进行进一步介绍。

Cornell Tech开源了LLMTune,这是一个可以在消费级显卡上微调大模型的框架,经过测试,可以在48G显存的显卡上微调4bit的650亿参数的LLaMA模型!
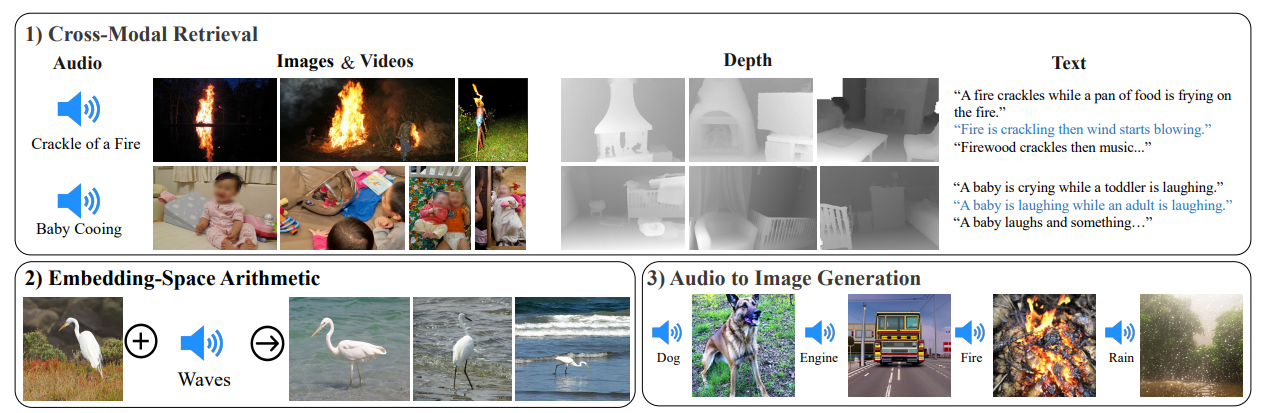
当前,大语言模型主要是基于生成式自然语言处理模型为主。少部分多模态模型可以处理文本、图片和视频信息。但是,AI模型目前还无法像人类一样接受周围的多模态信息进行处理,如图像、文本、声音等。但是,昨天MetaAI发布了一个可以听说读写的AI大模型ImageBind,它可以同时处理6种数据,并输出。本文将简单介绍一下这个模型。
今天,推特上一位科技博主SullyOmarr分享了一个关于embedding的内容十分火爆。主要介绍为什么embedding对于在目前的AI大模型中很重要。这是一个十分不错的关于embedding知识的介绍。本文将根据SullyOmarr的内容也对embedding做一个简单的介绍,并解释为什么它在大语言模型中十分重要。

大语言模型中一个非常重要的内容就是关于代码的支持。通常,基于代码数据训练的模型不仅在代码补全方面有着更好地支持,也可能是大语言模型逻辑能力的部分来源。本文将总结目前业界专门针对代码补全(生成)方面而做的8个大模型。

昨天,开源AI模型领域迎来一个重磅玩家,MosaicML发布MPT-7B系列模型,根据官方宣布的测试结果,MPT-7B的水平与MetaAI发布的LLaMA-7B水平差不多,属于当前开源领域最强大的模型。最重要的是,MPT-7B系列中有一个可以支持最多65k上下文输入的开源模型,比GPT-4的32k还高!应该是目前最长的!
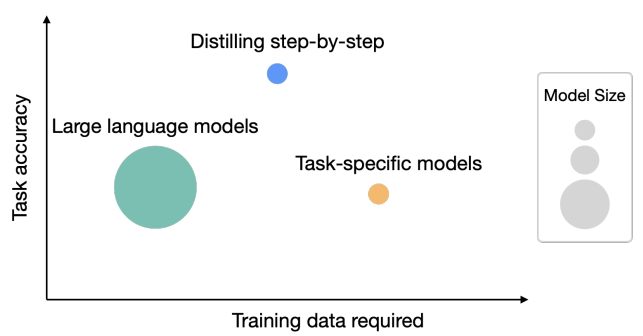
华盛顿大学研究人员与Google的研究人员一起在5月3日公布了一个新的方法,即逐步蒸馏(Distilling step-by-step),这个方法最大的特点有2个:一是需要更少的数据来做模型的蒸馏(根据论文描述,平均只需要之前方法的一半数据,最多只需要15%的数据就可以达到类似的效果);而是可以获得更小规模的模型(最多可以比原来模型规模小2000倍!)

5月4日,网络流传了一个所谓Google内部人员写的内部信,表达了Google和OpenAI这样的公司可能并不能在AI领域获得胜利的焦虑。里面说明了开源的AI模型发展迅速,不管是Google还是OpenAI都没有很好的护城河。
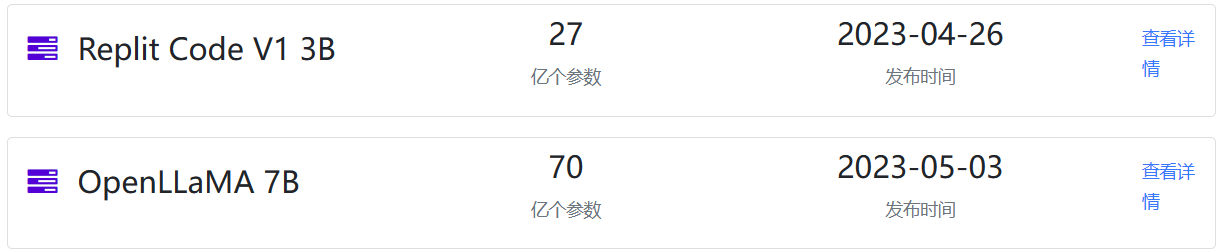
五一长假最后一天,AI技术的发展依然火热。今天有2个重磅的开源模型发布:一个是前几天提到的Replit的代码补全大模型Replit Code V1 3B,一个是UC Berkeley的博士生Hao Liu发起的一个开源LLaMA复刻项目。
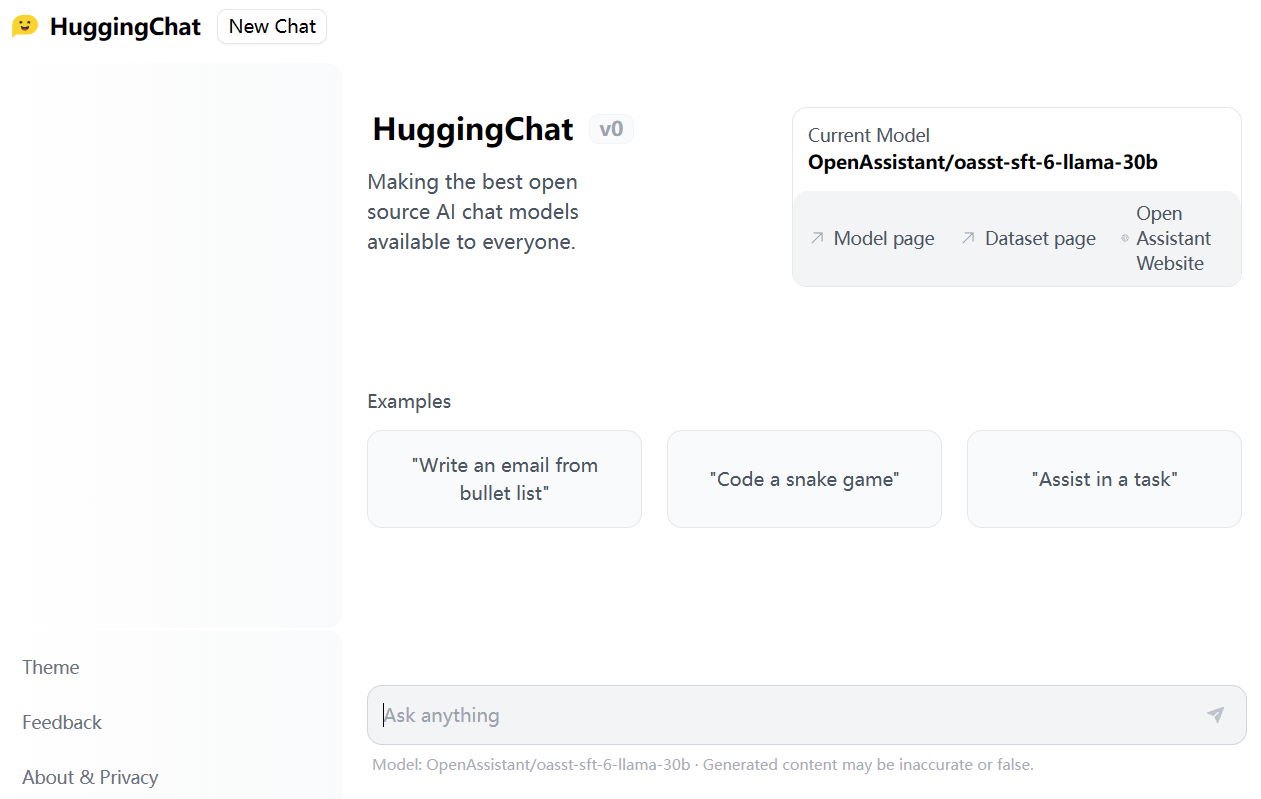
HuggingFace是近几年最火热的AI社区,在短短几年时间里已经称为AI模型的GitHub。目前,HuggingFace上已经托管了18万多的模型、3万多的数据集以及4万多的模型demo(spaces)。今天,HuggingFace发布了HuggingChat,声称要做最好的开源AI Chat项目,并且对所有人开放。

最近两天,关于AI技术和产品的进展依然很快。所以,我们本次直接给出一个AI技术进展快报。与大家分享一下最新的AI技术情况。
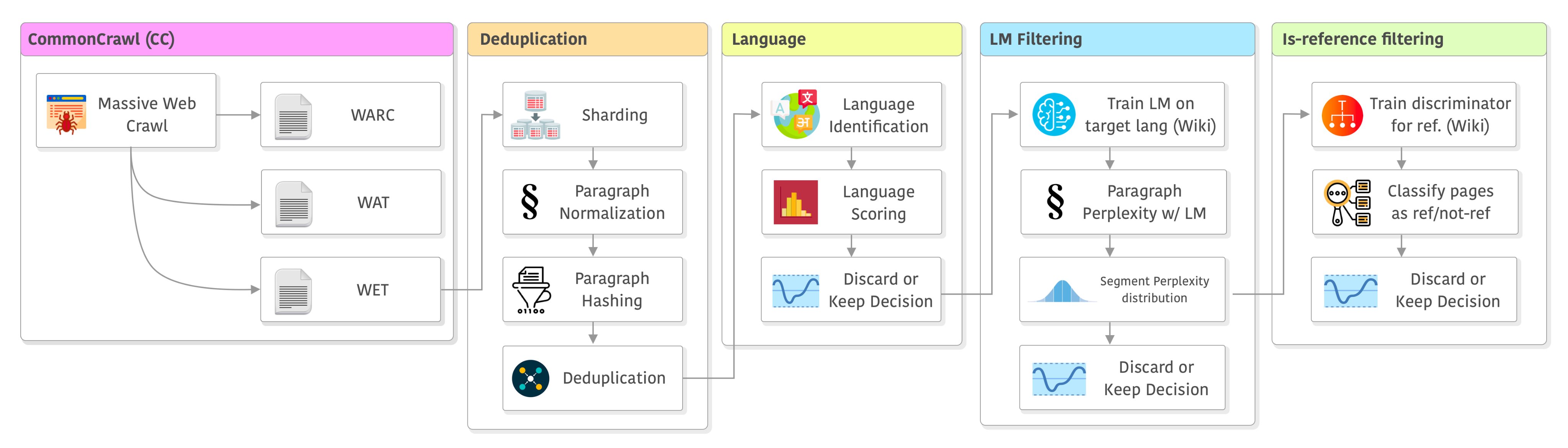
大语言模型的训练是一个十分复杂的技术,不仅涉及到模型的开发与部署,还涉及到数据的获取。与常规的算法模型不同的是,大语言模型通常需要大量的数据处理步骤。本文是根据英国一位自动工程师总结的大语言模型训练之前的数据处理步骤和决策过程。

今天下午,百度发布了文心一言大模型。这是一次对百度来说十分重要的发布会,也几乎是国内当前唯一一家将大模型作为一种大规模的服务推向市场的公司。本文主要介绍刚刚发布的文心一眼相关的能力。
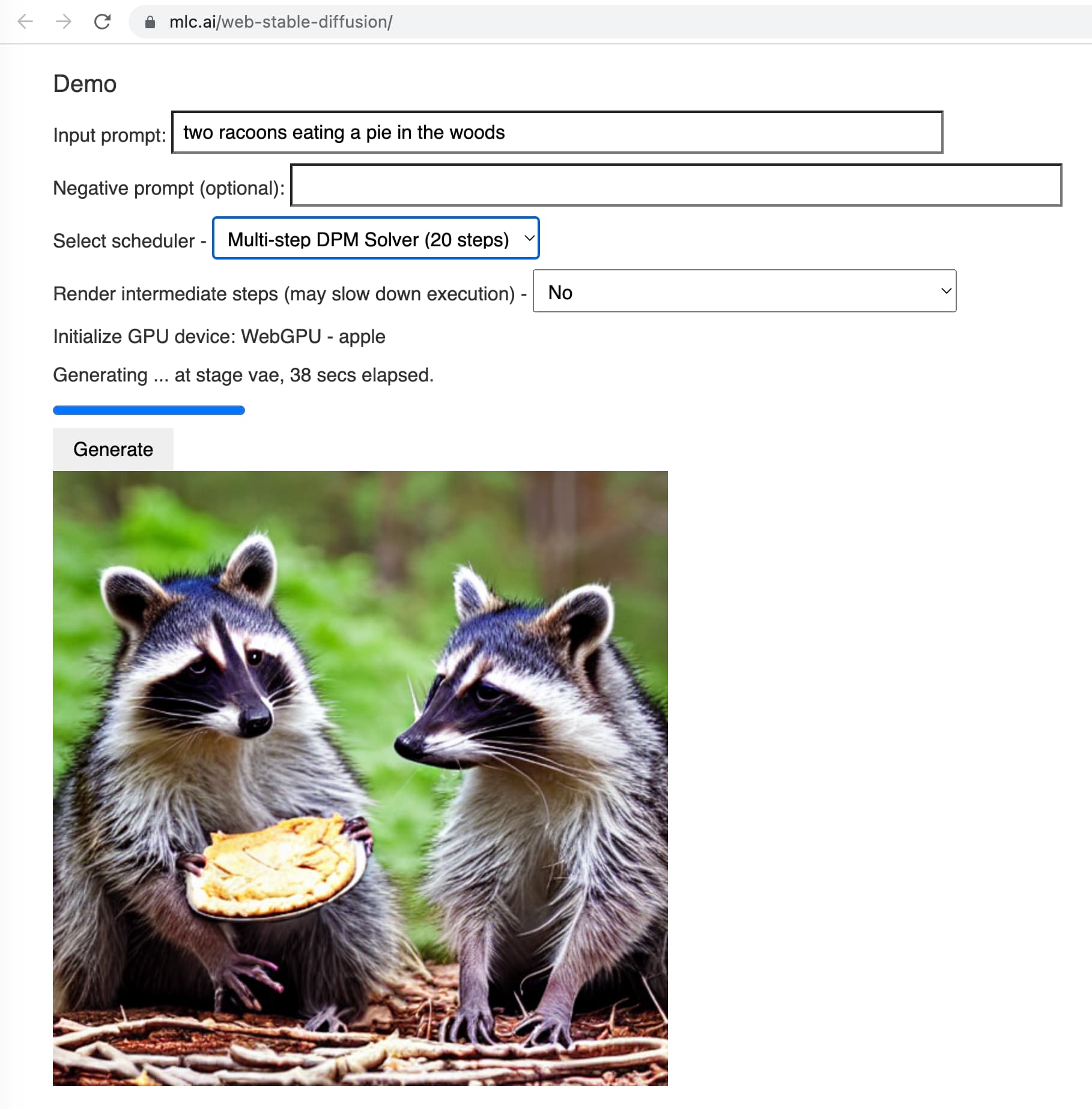
尽管当前ChatGPT和GPT-4非常火热,但是高昂的训练成本和部署成本其实导致大部分个人、学术工作者以及中小企业难以去开发自己的模型。使得使用OpenAI的官方服务几乎成为了一种无可替代的选择。本文介绍的是一种低成本开发高效ChatGPT的思路,我认为它适合一些科研机构去做,也适合中小企业创新的方式。这里提到的思路涉及了一些最近发表的成果和业界的一些实践产出,大家可以参考!
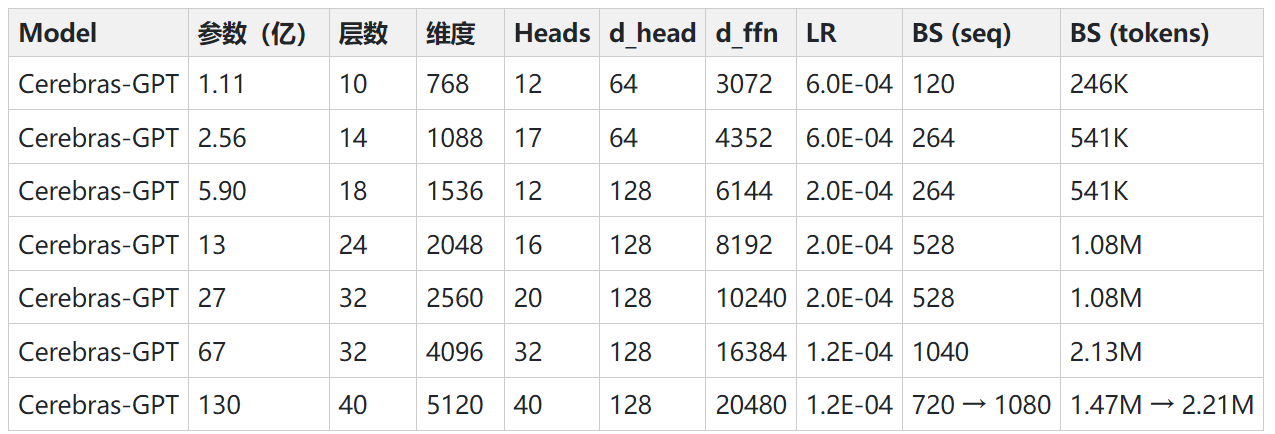
在最近的24个小时内,有2个开源的自然语言处理领域的开源预训练大模型发布。这两个模型都是类似GPT的Transformer模型,可以完成和ChatGPT类似的能力。最重要的是这2个模型完全开源!
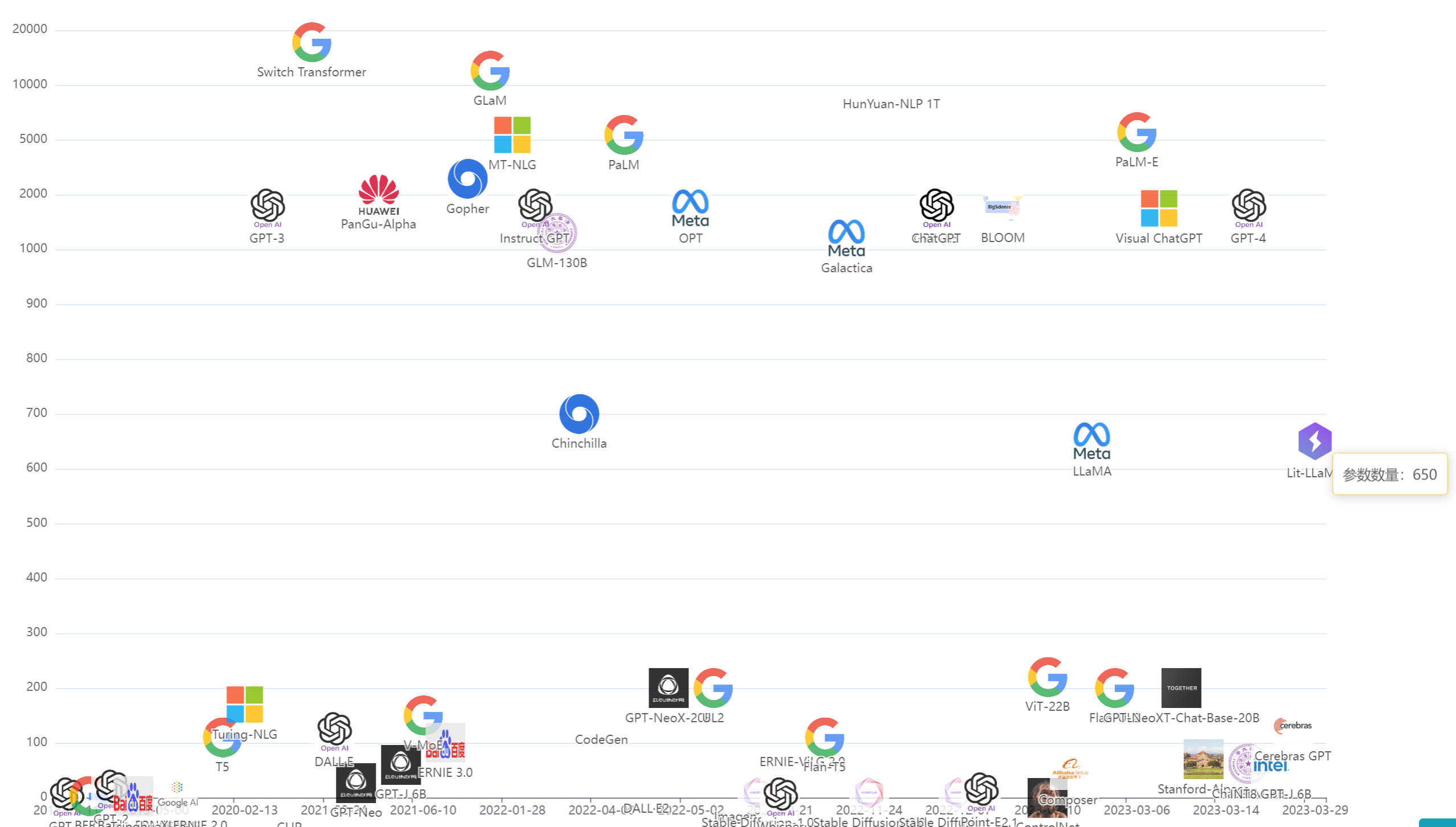
斯坦福大学发布的基础大模型追踪图谱Ecosystem Graphs,用图谱的方式给大家呈现了模型之间的联系,让人非常清楚明白追踪不同模型之间的关系。
本文主要描述了阿里眼中国内各家企业的大模型水平以及一些硬件算力的判断,同时结合部分其它信息整理。里面涉及到当前国内各大企业模型水平判断(如百度文心一言、华为盘古等)以及算力储备信息。

SAM全称是Segment Anything Model,由MetaAI最新发布的一个图像分割领域的预训练模型。该模型十分强大,并且有类似GPT那种基于Prompt的工作能力,在图像分割任务上展示了强大的能力!此外,该模型从数据集到训练代码和预训练结果完全开源!真Open的AI!
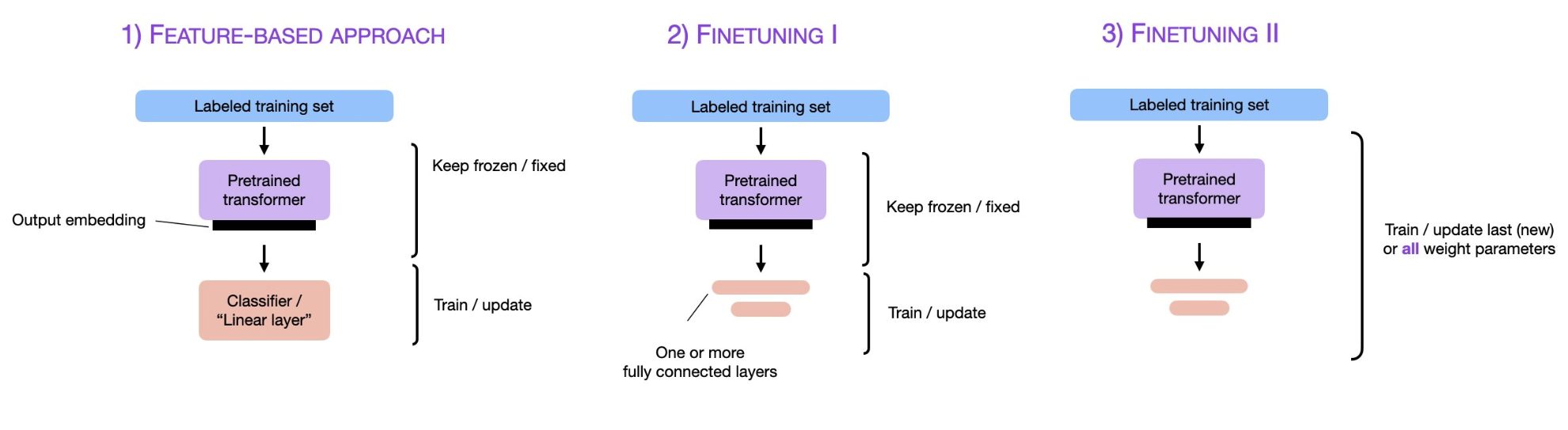
预训练大模型,尤其是大语言模型已经是当前最火热的AI技术。2018年Google发布BERT模型之后,fine-tuning技术也随之流行,即将预训练模型的权重冻结,然后根据具体任务进行微调变得十分有效且被应用在很多场景。而随着ChatGPT的火热,parameter-efficient fine-tuning和prompt-tuning技术似乎也有替代传统fine-tuning的趋势,本篇论文将简单描述预训练模型领域这三种微调技术及其差别。

随着预训练大模型技术的发展,基于prompt方式对模型进行微调获得模型输出已经是一种非常普遍的大模型使用方法。但是,对于同一个问题,使用不同的prompt也会获得不同的结果。为了获得更好的模型输出,对prompt进行调整,学习prompt工程技巧是一种必备的技能。
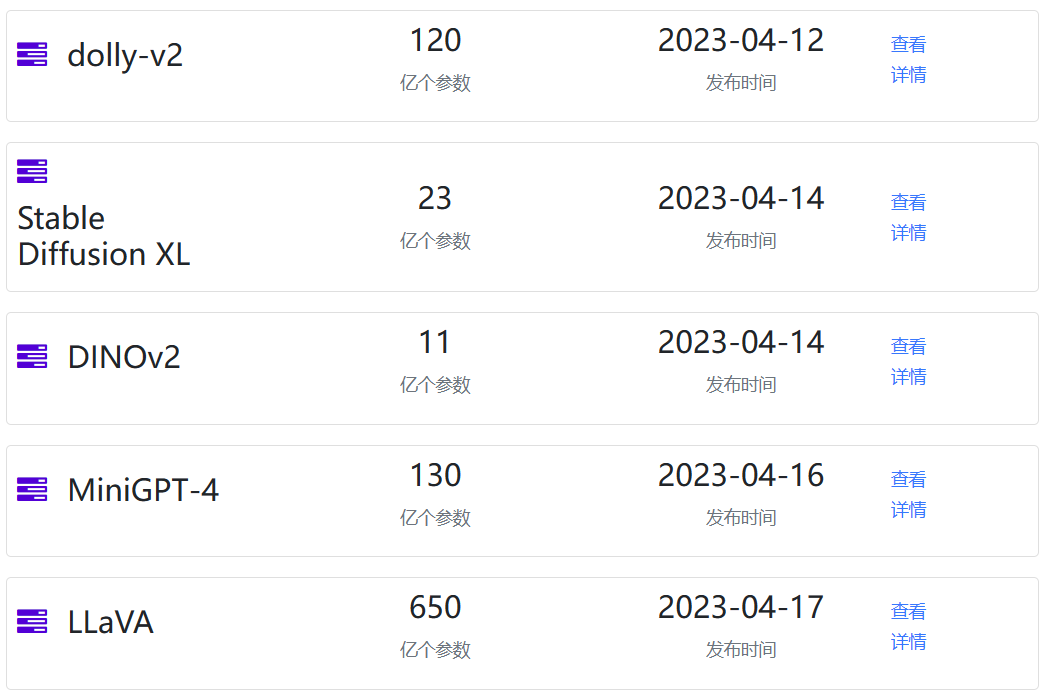
AI模型的发展速度令人惊讶,几乎每天都会有新的模型发布。而2023年4月中旬也有很多新的模型发布,我们挑出几个重点给大家介绍一下。
本文是Replit工程师发表的训练自己的大语言模型的过程的经验和步骤总结。Replit是一家IDE提供商,它们训练LLM的主要目的是解决编程过程的问题。Replit在训练自己的大语言模型时候使用了Databricks、Hugging Face和MosaicML等提供的技术栈。这篇文章提供的都是一线的实际经验,适合ML/AI架构师以及算法工程师学习。